En este artículo, exploraremos AWS CloudWatch, una herramienta de monitoreo y gestión versátil que recomendamos para proyectos de desarrollo en el sector salud. CloudWatch ofrece visibilidad en tiempo real sobre la infraestructura y las aplicaciones, lo que permite acciones oportunas para mantener el rendimiento y la fiabilidad.
Esto es especialmente importante en los sistemas de salud, que manejan datos sensibles de pacientes, proporcionan monitoreo continuo y ejecutan aplicaciones críticas donde incluso las menores interrupciones pueden afectar los flujos de trabajo clínicos y la disponibilidad de datos. El monitoreo en los sistemas de salud es esencial porque estos entornos operan en tiempo real, sin dejar margen para retrasos en la detección o respuesta. Esto hace que el monitoreo y la alerta en los sistemas de salud sean un componente crítico de una arquitectura de sistema fiable.
La Importancia del Monitoreo y las Alertas en el Sector Salud
Los sistemas de salud operan en entornos en tiempo real donde incluso las menores interrupciones pueden impactar directamente los flujos de trabajo clínicos y la eficiencia operativa.
En la práctica, las fallas rara vez se manifiestan como una interrupción completa del sistema. En cambio, aparecen como problemas pequeños pero críticos:
- El tiempo de inactividad de la API resulta en la falta de acceso a los Registros Electrónicos de Salud (EHR), retrasando los diagnósticos y las decisiones de tratamiento
- Las alertas retrasadas significan que los signos vitales anormales de los pacientes, como la frecuencia cardíaca o los niveles de oxígeno, no se escalan a tiempo
- Las integraciones fallidas impiden que los resultados de laboratorio o los datos de imágenes lleguen al equipo de atención
Aún cuando los sistemas se mantengan técnicamente operativos, estos problemas pueden interrumpir silenciosamente la entrega de atención. Los sistemas de monitoreo y alerta son esenciales porque detectan estas fallas temprano y permiten una respuesta rápida. Sin visibilidad adecuada, los equipos a menudo descubren problemas solo después de que empiezan a afectar a los usuarios o pacientes.
Incluso un breve retraso en la entrega de alertas (por ejemplo, de 30 a 60 segundos) puede impactar flujos de trabajo sensibles al tiempo, como el monitoreo en UCI o los sistemas de respuesta de emergencia, donde el tiempo de reacción es crítico.
Un monitoreo robusto asegura:
- Acceso continuo a sistemas críticos como EHR, monitoreo remoto de pacientes y plataformas de telemedicina
- Detección temprana de anomalías antes de que escalen a fallas mayores
- Flujo de datos fiable entre sistemas, especialmente en entornos con muchas integraciones
En el sector salud, el monitoreo no se trata solo de la estabilidad de la infraestructura. Se trata de mantener la integridad de los flujos de trabajo clínicos, donde el tiempo, la precisión y la disponibilidad de datos influyen directamente en los resultados.
Mejorando la Seguridad del Paciente con AWS CloudWatch
El monitoreo y la alerta de sistemas de salud desempeñan un papel crítico en el mantenimiento de la seguridad del paciente al garantizar que los datos estén disponibles, sean precisos y se entreguen a tiempo. En la práctica, esto requiere rastrear comportamientos específicos del sistema y reaccionar a las fallas de inmediato.
Registros Electrónicos de Salud (EHR)
Para los sistemas EHR, el acceso continuo a los datos de los pacientes depende de la estabilidad de los servicios backend y las bases de datos.
- Qué se está monitoreando: latencia de la API, tiempo de respuesta de la base de datos, tasas de error
- Tipo de alerta: alertas basadas en umbrales sobre picos de latencia y aumentos en la tasa de error
- Ejemplos de activación: El tiempo de respuesta de la API excede los límites definidos, las consultas a la base de datos se desaceleran, o las tasas de error aumentan por encima de los niveles normales
Monitorear estas métricas asegura un acceso ininterrumpido a los registros de pacientes y previene retrasos en la toma de decisiones clínicas.
Sistemas de Soporte a la Decisión Clínica (CDSS)
Las plataformas CDSS dependen del procesamiento oportuno de reglas clínicas y del intercambio de datos sin fisuras con sistemas externos.
- Qué se está monitoreando: tiempo de procesamiento de reglas, estado de integración con sistemas de laboratorio, retrasos en la ejecución del sistema
- Tipo de alerta: alertas basadas en eventos y alertas de latencia por procesamiento retrasado o fallido
- Ejemplos de activación: Ejecución retrasada de reglas clínicas, llamadas a la API fallidas a sistemas de laboratorio, o falta de datos de entrada
Las alertas se pueden activar cuando las reglas clínicas no se procesan a tiempo o cuando las integraciones fallan, reduciendo el riesgo de recomendaciones perdidas o decisiones de tratamiento incorrectas.
Monitoreo Remoto de Pacientes (RPM)
Los sistemas RPM dependen de un flujo continuo de datos de dispositivos médicos y del análisis en tiempo real de los signos vitales del paciente.
- Qué se está monitoreando: conectividad del dispositivo, tasa de ingestión de datos, umbrales vitales anormales
- Tipo de alerta: alertas en tiempo real por falta de datos o métricas anormales del paciente
- Ejemplos de activación: desconexiones del dispositivo, caída en la frecuencia de transmisión de datos, o signos vitales que exceden umbrales predefinidos
Estas alertas aseguran que los equipos de atención sean notificados de inmediato tanto de problemas técnicos como de riesgos potenciales para el paciente, lo que permite una intervención más rápida.
Optimización de Costos y Eficiencia con AWS CloudWatch
Los costos en la nube pueden crecer rápidamente en entornos de atención médica si no se gestionan. En los entornos de atención médica de AWS CloudWatch, la optimización de costos depende de la visibilidad en los controladores de costos específicos en lugar de en el rendimiento general del sistema.
En la práctica, esto significa identificar dónde se generan los costos y optimizar el comportamiento del sistema en función de los patrones de uso reales.
Los factores de costo más comunes en sistemas de salud basados en AWS incluyen:
- Duración de la ejecución de Lambda — tiempos de ejecución más largos aumentan directamente los costos de cómputo
- Conteo de invocaciones — los disparadores de alta frecuencia (especialmente en sistemas impulsados por eventos) pueden aumentar significativamente el uso total
- Volumen de registros — el registro excesivo o desestructurado conduce a altos costos de almacenamiento e ingestión
- Almacenamiento de métricas — grandes volúmenes de métricas personalizadas, especialmente con alta granularidad, pueden aumentar los gastos de monitoreo
CloudWatch proporciona información detallada en estas áreas, permitiendo a los equipos rastrear patrones de uso y realizar optimizaciones específicas.
En lugar de analizar ampliamente el comportamiento del sistema, los equipos pueden identificar exactamente dónde se generan los costos y tomar medidas, como reducir el tiempo de ejecución de Lambda, limitar invocaciones innecesarias u optimizar estrategias de registro.
Ejemplo de la práctica
Por ejemplo, descubrimos que ciertas funciones de AWS Lambda en uno de nuestros proyectos de salud consumían hasta $300 al mes. Al analizar las métricas de CloudWatch, optimizamos las funciones y reducimos los costos a solo $20–30, lo que resultó en ahorros de casi $1,000.
Los principales factores de costo que típicamente vemos son el tiempo de ejecución ineficiente de Lambda, el registro excesivo y mecanismos de reintento no optimizados.
¿Qué es AWS CloudWatch?
Amazon CloudWatch es un servicio de monitoreo y observabilidad diseñado para proporcionar visibilidad en tiempo real sobre aplicaciones, infraestructura y comportamiento del sistema.
En sistemas de salud, donde múltiples servicios, integraciones y flujos de datos operan simultáneamente, CloudWatch actúa como una capa centralizada que recopila y correlaciona datos operativos en todo el sistema.
CloudWatch opera en tres capas principales — métricas, registros y eventos — que juntas permiten una observabilidad completa de sistemas distribuidos.
Agrega tres tipos de datos centrales:
- Métricas — indicadores de rendimiento como latencia, uso de CPU, tasas de error y volumen de solicitudes
- Registros — registros detallados de eventos del sistema, comportamiento de la aplicación y errores
- Eventos — cambios en el sistema, disparadores y respuestas automáticas
Esta vista unificada permite a los equipos detectar problemas más rápido, entender su causa raíz y responder antes de que impacten en los flujos de trabajo clínicos.
CloudWatch no es solo una herramienta de monitoreo, sino una capa de control operativo que permite:
- Visibilidad del sistema en tiempo real a través de aplicaciones de salud distribuidas
- Detección proactiva de problemas a través de umbrales y detección de anomalías
- Respuestas automáticas a eventos del sistema (por ejemplo,, escalado, reinicios, notificaciones)
En entornos de atención médica complejos, donde los sistemas incluyen plataformas de EHR, dispositivos IoT, APIs e integraciones de terceros, este nivel de visibilidad es esencial para mantener la confiabilidad del sistema y la integridad de los datos. Como resultado, CloudWatch se convierte en un componente clave de la observabilidad en salud en sistemas modernos basados en la nube.
Características Clave de CloudWatch para la Salud
CloudWatch proporciona un conjunto de características fundamentales que apoyan la observabilidad en salud, la respuesta rápida a incidentes y el control operacional en sistemas de atención médica.
Alertas y Notificaciones Automatizadas
Qué hace:
CloudWatch activa alertas cuando se detectan umbrales predefinidos o patrones de anomalías, notificando a los equipos a través de canales de comunicación integrados.
Por qué es importante en salud:
Permite una respuesta inmediata a problemas críticos como fallos en la API, alta latencia o intentos de acceso no autorizados antes de que impacten en los flujos de trabajo clínicos o en la atención al paciente.
Ejemplo:
Por ejemplo, se puede activar una alerta cuando las tasas de error superan un umbral definido o cuando se detectan intentos de acceso no autorizado, permitiendo que los equipos respondan antes de que se comprometa la seguridad o la integridad de los datos.
Integración con AWS Lambda
Qué hace:
CloudWatch se integra con AWS Lambda para activar acciones automatizadas en respuesta a eventos del sistema, como reintentar procesos fallidos, reiniciar servicios o escalar la infraestructura.
Por qué es importante en salud:
Apoya la respuesta automática a incidentes, permitiendo que los sistemas se autoconserven sin intervención manual. Esto es especialmente importante en entornos sensibles al tiempo donde los retrasos en la respuesta pueden interrumpir la entrega de atención.
Ejemplo:
Por ejemplo, si una función de procesamiento de datos falla, CloudWatch puede activar automáticamente un mecanismo de reintento o reinicio, asegurando que los datos críticos del paciente se procesen sin intervención manual.
Detección de Anomalías impulsada por IA
Qué hace:
CloudWatch utiliza modelos de aprendizaje automático para detectar patrones inusuales en el comportamiento del sistema, incluso cuando no se definen umbrales fijos.
Por qué es importante en salud:
Ayuda a detectar comportamientos anormales del sistema, como picos inesperados en el uso de la API o caídas en los datos de dispositivos médicos, lo que permite una resolución proactiva de problemas antes de que afecte la atención al paciente.
Ejemplo:
Por ejemplo, una caída repentina en los datos entrantes de dispositivos médicos conectados puede señalar un fallo del dispositivo o problemas de conectividad, lo que permite a los equipos investigar antes de que se vea afectada la monitorización del paciente.
Cómo Funciona AWS CloudWatch
CloudWatch opera como un ciclo de monitoreo continuo que recopila, procesa y actúa sobre los datos del sistema en tiempo real. Este proceso se puede representar como un bucle que consta de cuatro etapas clave:
Recoger
CloudWatch recopila métricas y registros de recursos de AWS, aplicaciones y sistemas conectados, incluidos servidores, APIs, bases de datos y dispositivos IoT.
Monitorear
Los datos recopilados se visualizan a través de paneles de control, lo que permite a los equipos rastrear el comportamiento del sistema, correlacionar métricas y registros, e identificar problemas de rendimiento o anomalías.
Actuar
Cuando se superan los umbrales predefinidos o se detectan patrones inusuales, CloudWatch activa alertas o respuestas automatizadas, como escalar la infraestructura o reiniciar servicios.
Analizar
CloudWatch permite un análisis más profundo del comportamiento del sistema utilizando datos históricos, métricas de alta resolución y herramientas como Metric Math para identificar tendencias y optimizar el rendimiento.
De acuerdo con este flujo, CloudWatch permite un proceso de monitoreo totalmente automatizado donde los datos son recopilados, analizados y utilizados para activar acciones de forma continua.
En los sistemas de salud, este ciclo es crítico porque permite la detección automática de anomalías, como latencias anormales de API o fallos en el procesamiento de datos. Estos problemas pueden activar inmediatamente alertas y acciones automatizadas de escalado o recuperación sin intervención manual, asegurando que los sistemas clínicos permanezcan receptivos y confiables. Este enfoque es esencial para un monitoreo efectivo en sistemas de salud y alertas en tiempo real, donde se requiere una respuesta inmediata.
Estudio de Caso: AWS CloudWatch en un Entorno de Salud
Examinemos cómo se implementó AWS CloudWatch para proyectos de salud en uno de nuestros proyectos de salud: una plataforma de monitoreo remoto de pacientes utilizada por clínicas y pacientes.
Contexto del Proyecto
- Construido en infraestructura de AWS
- Más de 500 funciones de AWS Lambda
- Dos plataformas: web (para profesionales) y móvil (para pacientes)
- Más de 20,000 usuarios en las plataformas
- Más de 500 grupos de registros y más de 1,400 métricas monitoreadas
Este fue un sistema de alto rendimiento y en tiempo real con procesamiento continuo de datos, donde los datos de los pacientes, las señales de los dispositivos y los eventos del sistema se procesaron sin interrupciones.
Recolección y Visualización de Datos
Recopilamos grandes volúmenes de registros, métricas y eventos de múltiples servicios de AWS, incluidos:
- API Gateway — tasas de solicitud, latencia, respuestas de error
- AWS Lambda — duración de ejecución, recuento de invocaciones, tasas de error
- DynamoDB — uso de capacidad de lectura/escritura, eventos de limitación
CloudWatch consolida estos datos en un panel centralizado, proporcionando visibilidad en tiempo real del comportamiento del sistema.
Esto permite a los equipos identificar rápidamente:
- cuellos de botella en el rendimiento
- servicios fallidos
- comportamiento anormal del sistema
y rastrear los problemas hasta su origen exacto.
Configuración de Alertas, Métricas y Eventos
Configuramos alertas basadas en umbrales críticos del sistema y eventos en tiempo real.
Ejemplos de alertas incluyen:
- Alertas de latencia activadas cuando el tiempo de respuesta de la API supera los umbrales definidos (por ejemplo, >300–500 ms)
- Alertas de tasa de errores activadas cuando las tasas de errores superan niveles aceptables (por ejemplo, >2–5%)
- Alertas de acceso no autorizado activadas ante intentos de autenticación sospechosos o patrones de acceso inusuales
Estas alertas pueden definirse en código o configurarse directamente en CloudWatch.
Las métricas y los eventos también se utilizan para automatizar el comportamiento del sistema, como:
- escalar la infraestructura bajo carga aumentada
- activar notificaciones para equipos operativos
- iniciar acciones de recuperación para procesos fallidos
Impacto
Con esta configuración, el sistema logró:
- Detección y resolución más rápidas de problemas de rendimiento
- Reducción del tiempo de inactividad en los servicios orientados al paciente
- Mejoras en la confiabilidad del procesamiento de datos en tiempo real
- Mejor control sobre el comportamiento de la infraestructura bajo carga
Lo más importante es que el sistema de monitoreo aseguró que los flujos de trabajo críticos de atención médica permanecieran estables y receptivos, incluso bajo alta carga y flujos de datos continuos.
Ejemplos de Uso de CloudWatch en Nuestro Proyecto de Salud
Veamos más de cerca cómo funciona CloudWatch dentro del proyecto de salud que presentamos anteriormente.
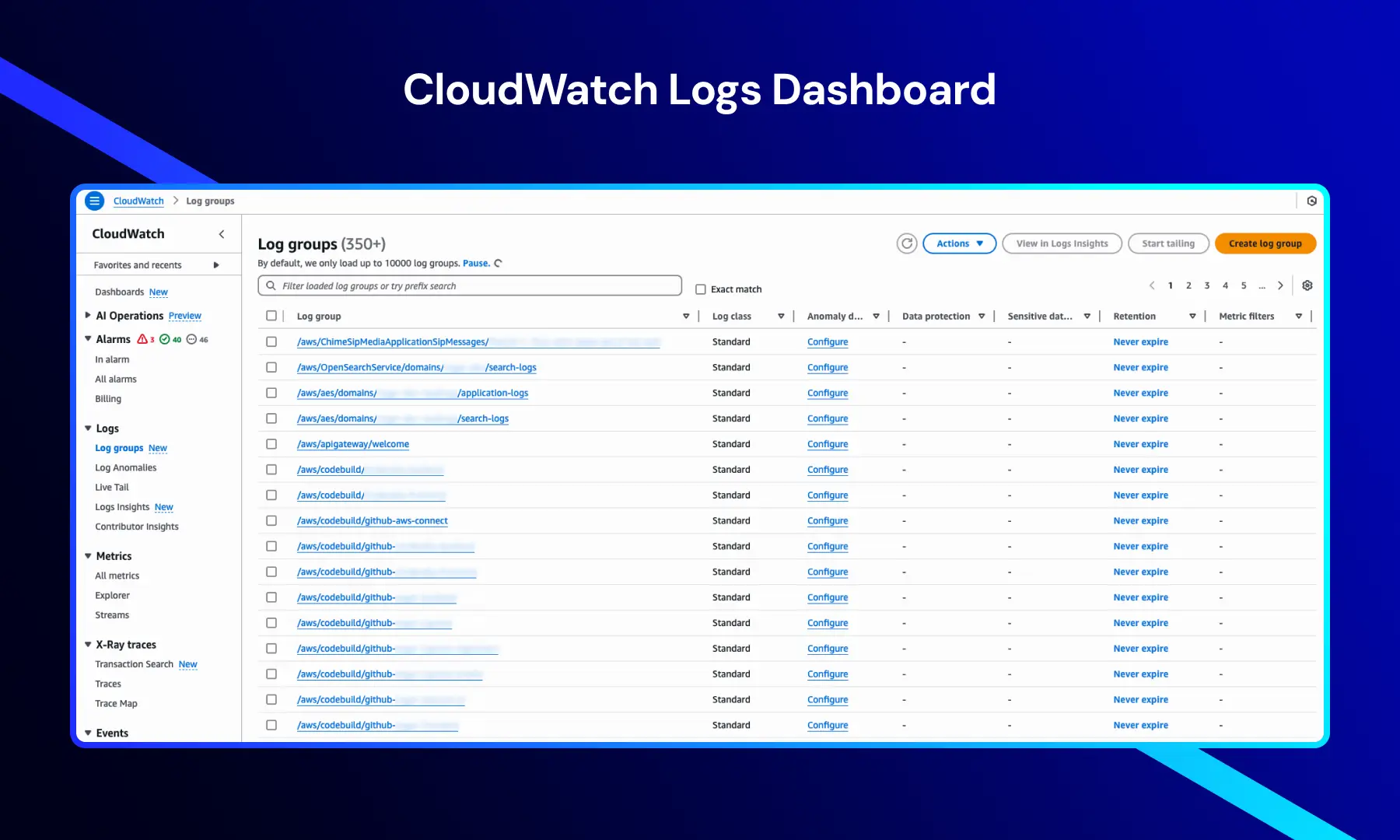
Dashboard de Registros de CloudWatch
Esta vista muestra grupos de registros que organizan y almacenan registros de diferentes servicios y recursos de AWS.
Proporciona información clave como:
- Nombres de grupos de registros — registros generados por aplicaciones, infraestructura y servicios de AWS
- Clase de registro — típicamente configurada como Estándar para el manejo de registros por defecto
- Configuraciones de retención — a menudo configuradas como “Nunca expirar” para análisis a largo plazo
- Configuración de detección de anomalías — habilitando la identificación de patrones de registro inusuales
Opciones de navegación como Alarms, Metrics, X-Ray traces, y Events proporcionan acceso a todas las capacidades de monitoreo y análisis de CloudWatch.
Esta vista es esencial para la gestión centralizada de registros y la solución de problemas eficientes en sistemas distribuidos.
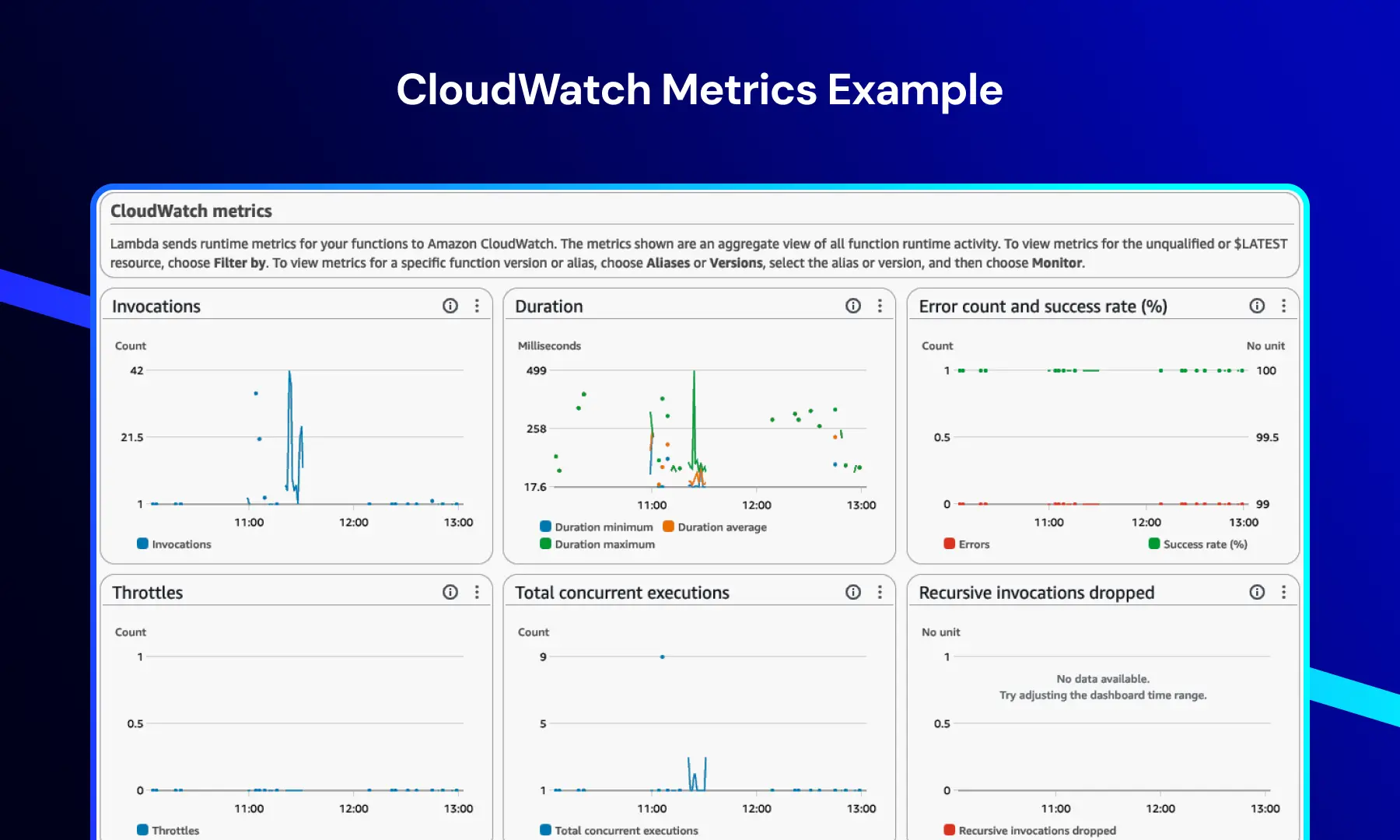
Métricas de CloudWatch
Este dashboard proporciona información en tiempo real sobre el rendimiento del sistema y de las aplicaciones.
Incluye típicamente:
- Invocaciones de funciones
- Duración de ejecución
- Tasas de error
- Eventos de limitación
Esto permite a los equipos monitorear las tendencias de rendimiento, detectar cuellos de botella y mantener la estabilidad del sistema bajo carga.
Métricas de Funciones Lambda
Este panel se centra en métricas de rendimiento detalladas para funciones de AWS Lambda.
Los conocimientos clave incluyen:
- Invocaciones más costosas — identificando funciones con el mayor consumo de recursos
- Duración de ejecución vs duración facturada — comprendiendo el comportamiento de costos basado en las reglas de facturación de AWS
- Acceso a registros detallados — permitiendo una depuración rápida y optimización del rendimiento
Este nivel de visibilidad es crítico para optimizar tanto el rendimiento como los costos de infraestructura en sistemas de salud impulsados por eventos.

![Cloud Software Development [AWS].webp](/static/Cloud_Software_Development_AWS_a351611d38.webp)
Beneficios de AWS CloudWatch para la Salud
CloudWatch proporciona a los sistemas de salud la visibilidad y el control necesarios para mantener el rendimiento, la fiabilidad y la seguridad en entornos complejos y en tiempo real.
Los beneficios clave incluyen:
Observabilidad completa a través de los sistemas
CloudWatch permite la observabilidad de salud de extremo a extremo a través de APIs, bases de datos, infraestructura y dispositivos médicos conectados, permitiendo a los equipos comprender el comportamiento del sistema en tiempo real y detectar rápidamente las anomalías.
Respuesta a incidentes más rápida
Las alertas automatizadas y el monitoreo en tiempo real reducen el tiempo de respuesta, ayudando a los equipos a detectar y resolver problemas antes de que impacten los flujos de trabajo clínicos o el cuidado del paciente.
Reducción del tiempo de inactividad
La detección temprana de anomalías y las acciones de recuperación automatizadas minimizan las interrupciones del servicio en sistemas de salud críticos.
Eficiencia operativa mejorada
La clara visibilidad del rendimiento del sistema permite a los equipos optimizar el uso de recursos y mantener un comportamiento del sistema estable bajo diversas condiciones de carga.
Cumplimiento y seguridad mejorados
El monitoreo continuo y el registro respaldan los requisitos de auditoría y ayudan a detectar accesos no autorizados o actividad inusual del sistema.
Escalabilidad
CloudWatch se escala con el crecimiento del sistema, soportando volúmenes de datos, usuarios y dispositivos conectados en aumento sin pérdida de visibilidad.
¿Es posible no usar CloudWatch?
Sí, existen alternativas a CloudWatch y, en algunos casos, pueden ser más adecuadas dependiendo de la arquitectura del sistema y las preferencias del equipo.
Las alternativas comunes incluyen:
- Datadog — ofrece capacidades de monitoreo avanzadas con una interfaz de usuario robusta y herramientas de visualización ricas
- Prometheus + Grafana — solución de código abierto que proporciona recogida y visualización de métricas flexibles, a menudo utilizada en entornos personalizados o de múltiples nubes
- Elastic Stack (ELK) — enfocado en la gestión y búsqueda centralizada de registros
- New Relic — proporciona observabilidad de pila completa con un sólido soporte para el monitoreo del rendimiento de aplicaciones
Sin embargo, la elección depende en gran medida de cuán estrechamente esté integrado su sistema con AWS.
Resumen de Comparación
| Herramienta | Ventaja Clave | Compensaciones |
|---|---|---|
| Datadog | Mejor interfaz de usuario y experiencia de usuario | Costo más alto a gran escala |
| Prometheus | Altamente flexible y personalizable | Configuración y mantenimiento complejos |
| CloudWatch | Mejor ajuste para sistemas nativos de AWS | Flexibilidad limitada fuera de AWS |
CloudWatch sigue siendo una opción práctica para sistemas de salud basados en AWS debido a su integración nativa, menor carga operativa y escalabilidad sin interrupciones.
Para equipos que operan completamente dentro de AWS, reduce la necesidad de herramientas adicionales y simplifica la arquitectura de monitoreo sin comprometer la visibilidad o el control.
Pasos de Implementación para AWS CloudWatch
Implementar CloudWatch en sistemas de salud requiere no solo una configuración adecuada, sino también un enfoque estructurado para evitar errores comunes que pueden afectar el rendimiento, los costos y la confiabilidad.
1. Configurar Monitoreo
Habilite CloudWatch para todos los servicios relevantes de AWS y defina las métricas clave que reflejen la salud y el rendimiento del sistema.
- Configure el monitoreo para APIs, bases de datos, servicios de computación e integraciones
- Instale Agentes de CloudWatch donde sea necesario (por ejemplo, para servidores personalizados)
- Enfóquese en métricas críticas como latencia, tasas de error y carga del sistema
Mejor práctica:
Comience con un conjunto mínimo pero significativo de métricas relacionadas con riesgos reales del sistema (por ejemplo, latencia de API, solicitudes fallidas, retrasos de datos).
Qué no hacer:
Evite rastrear demasiadas métricas desde el principio: esto crea ruido, aumenta los costos y hace más difícil identificar problemas reales.
2. Configurar Tableros y Alertas
Crear tableros y alertas que reflejen prioridades operativas reales en lugar de métricas genéricas del sistema.
- Construya tableros para flujos de trabajo clave (por ejemplo., flujo de datos de pacientes, rendimiento de la API)
- Establecer alertas para latencia, tasas de error y comportamiento anormal del sistema
- Definir umbrales basados en el uso real del sistema, no en suposiciones
Mejor práctica:
Alinear alertas con escenarios críticos para el negocio, como el acceso retrasado a los registros de pacientes o la entrega fallida de datos.
Qué no hacer:
Evitar alertas demasiado sensibles o umbrales mal definidos: esto conduce a la fatiga por alertas y notificaciones ignoradas.
3. Automatizar Respuestas
Usar integraciones de CloudWatch para automatizar reacciones del sistema a incidentes.
- Activar funciones de AWS Lambda para reintentos, escalado o acciones de recuperación
- Configurar autoescalado basado en carga y métricas de rendimiento
- Integrar notificaciones con herramientas de gestión de incidentes
Mejor práctica:
Automatizar respuestas para fallas predecibles (por ejemplo, reintentos para errores transitorios, escalado durante picos de tráfico).
Qué no hacer:
No depender completamente de la intervención manual: en sistemas de salud, las respuestas retrasadas pueden impactar directamente la fiabilidad del sistema.
4. Probar y Optimizar Continuamente
El monitoreo no es una configuración única: requiere pruebas y optimización regulares.
- Validar que las alertas se activen correctamente
- Simular escenarios de falla (por ejemplo, tiempo de inactividad de la API, retrasos en los datos)
- Revisar y ajustar regularmente umbrales, métricas y lógica de alertas
Mejor práctica:
Refinar continuamente el monitoreo basado en incidentes reales y comportamiento del sistema.
Qué no hacer:
Evitar un enfoque de “configurar y olvidar”: las configuraciones obsoletas a menudo pasan por alto problemas críticos o generan alertas irrelevantes.
Conclusión
AWS CloudWatch es una opción práctica para el monitoreo de sistemas de salud en entornos de AWS, proporcionando la visibilidad, alertas y control de costos requeridos para entornos de producción.
En arquitecturas de salud complejas, donde múltiples servicios, integraciones y flujos de datos en tiempo real deben operar de manera confiable, CloudWatch permite a los equipos mantener la estabilidad, detectar problemas a tiempo y responder sin demora.
Cuando se implementa correctamente, apoya la observabilidad total, una respuesta más rápida a incidentes y un comportamiento del sistema más predecible bajo carga.
A medida que los sistemas de salud continúan escalando y volviéndose más orientados a los datos, tener una estrategia de monitoreo y alerta bien definida ya no es opcional: es una parte esencial de la construcción de software confiable y mantenible.
Si está diseñando o escalando una plataforma de salud en AWS, una configuración bien configurada de CloudWatch puede reducir significativamente los riesgos operativos y mejorar el rendimiento del sistema.
¿Necesita ayuda para implementar CloudWatch en su proyecto de salud?
En JetBase, ayudamos a los equipos de salud a diseñar sistemas de monitoreo que van más allá de la configuración básica, centrándonos en la fiabilidad, la eficiencia de costos y el rendimiento en el mundo real.
Ya sea que estés construyendo una nueva plataforma o optimizando una existente, podemos ayudarte a establecer una estrategia de monitoreo que se ajuste a tu arquitectura y objetivos comerciales.
Contáctanos para discutir tu proyecto o obtener una consulta.