I denne artikkelen vil vi utforske AWS CloudWatch—et allsidig overvåkings- og administrasjonsverktøy som vi anbefaler for utviklingsprosjekter innen helsevesenet. CloudWatch tilbyr sanntidsinnsyn i infrastruktur og applikasjoner, noe som muliggjør raske tiltak for å opprettholde ytelse og pålitelighet.
Dette er spesielt viktig i helsesystemer, som håndterer sensitiv pasientdata, gir kontinuerlig overvåking og kjører kritiske applikasjoner der selv mindre forstyrrelser kan påvirke kliniske arbeidsflyter og datatilgjengelighet. Overvåking i helsesystemer er essensielt fordi disse miljøene opererer i sanntid, noe som etterlater ingen rom for forsinkelser i oppdagelse eller respons. Dette gjør overvåking og varsling i helsesystemer til en kritisk komponent av pålitelig systemarkitektur.
Viktigheten av Overvåking og Varsler i Helsevesenet
Helsesystemer opererer i sanntidsmiljøer der selv små forstyrrelser kan direkte påvirke kliniske arbeidsflyter og operasjonell effektivitet.
I praksis ser svikt sjelden ut som en komplett systemfeil. I stedet fremstår de som små, men kritiske problemer:
- API-nedetid resulterer i ingen tilgang til Elektroniske Pasientjournaler (EPJ), noe som forsinker diagnose og behandlingsbeslutninger
- Forsinkede varsler betyr at unormale pasientvitaler, som hjertefrekvens eller oksygennivåer, ikke heves i tide
- Mislykkede integrasjoner forhindrer laboratorieresultater eller bildedata fra å nå behandlingsteamet
Selv når systemene forblir teknisk operative, kan disse problemene stille forstyrre omsorgslevering. Overvåkings- og varslingssystemer er essensielle fordi de oppdager disse sviktene tidlig og muliggjør rask respons. Uten riktig oversikt oppdager team ofte problemer først etter at de begynner å påvirke brukere eller pasienter.
Selv en kort forsinkelse i varsling (for eksempel 30–60 sekunder) kan påvirke tidsfølsomme arbeidsflyter som overvåking av intensivavdeling eller nødresponsystemer, der responstid er avgjørende.
Robust overvåking sikrer:
- Kontinuerlig tilgang til kritiske systemer som EPJ, fjernovervåking av pasienter og telemedisinplattformer
- Tidlig oppdagelse av anomalier før de utvikler seg til større svikt
- Pålitelig datatilgang mellom systemer, spesielt i integrasjonsrike miljøer
I helsesektoren handler overvåking ikke bare om infrastrukturens stabilitet. Det handler om å opprettholde integriteten til kliniske arbeidsflyter, der timing, nøyaktighet og datatilgjengelighet direkte påvirker resultatene.
Forbedring av Pasientsikkerhet med AWS CloudWatch
Overvåking og varsling i helsesystemer spiller en kritisk rolle i å opprettholde pasientsikkerhet ved å sikre at data er tilgjengelig, nøyaktig og levert i tide. I praksis krever dette å spore spesifikke systematferder og reagere på svikt umiddelbart.
Elektroniske Pasientjournaler (EPJ)
For EPJ-systemer avhenger kontinuerlig tilgang til pasientdata av stabiliteten til backend-tjenester og databaser.
- Hva overvåkes: API-latens, databasens responstid, fe率
- Type varsling: Grenseverdi-basert varsling ved latensspikes og økning i feRates
- Eksempler på triggere: API-responstid overskrider definerte grenser, databaseforespørslene blir tregere, eller feRates stiger over normale nivåer
Overvåkning av disse målingene sikrer uavbrutt tilgang til pasientregistre og forhindrer forsinkelser i kliniske beslutningsprosesser.
Kliniske beslutningsstøttesystemer (CDSS)
CDSS-plattformer er avhengige av tidsriktig behandling av kliniske regler og sømløs datautveksling med eksterne systemer.
- Hva overvåkes: Behandlingstid for regler, integrasjonsstatus med laboratorie systemer, systemutførelsesforsinkelser
- Type varsling: Hendelsesbaserte og latensvarsler for forsinket eller mislykket behandling
- Eksempler på triggere: Forsinket utførelse av kliniske regler, mislykkede API-anrop til laboratorie systemer, eller manglende inndata
Varsler kan utløses når kliniske regler ikke behandles i tide eller når integrasjoner mislykkes, noe som reduserer risikoen for å gå glipp av anbefalinger eller feil behandlingsbeslutninger.
Fjernovervåkning av pasienter (RPM)
RPM-systemer er avhengige av kontinuerlig datatilførsel fra medisinske enheter og sanntidsanalyse av pasientvitaler.
- Hva overvåkes: Enhetstilkobling, datainntaksfrekvens, unormale vitale terskler
- Type varsling: Sanntidsvarsler for manglende data eller unormale pasientmålinger
- Eksempler på triggere: Enheten kobles fra, fall i datatransmisjonsfrekvens, eller vitale overskrider forhåndsdefinerte terskler
Dessse varslene sikrer at pleieteam umiddelbart varsles om både tekniske problemer og potensielle pasientrisikoer, som muliggjør raskere intervensjon.
Kostnadsoptimalisering og effektivitet med AWS CloudWatch
Cloudkostnader kan vokse raskt i helsemiljøer hvis de ikke forvaltes. I AWS CloudWatch helsemiljøer avhenger kostnadsoptimalisering av synlighet i spesifikke kostnadsdrivere snarere enn generell systemytelse.
I praksis betyr dette å identifisere hvor kostnadene genereres og optimalisere systematferd basert på reelle bruks mønstre.
De vanligste kostnadsdriverne i AWS-baserte helsesystemer inkluderer:
- Lambda-utkjøringsvarighet — lengre uavbrutte tidsrom øker direkte databehandlingskostnadene
- Invokasjonsantall — høyfrekvente utløserne (spesielt i hendelsesdrevne systemer) kan betydelig øke totalforbruket
- Loggvolum — overflødig eller ustrukturert logging fører til høye lagrings- og inntaks kostnader
- Metrikk lagring — store volumer av tilpassede metrikk, spesielt med høy granularitet, kan øke overvåkingskostnadene
CloudWatch gir detaljerte innsikter i disse områdene, slik at team kan følge med på bruksmodeller og gjøre målrettede optimaliseringer.
I stedet for å analysere systematferd på bred basis, kan teamet identifisere nøyaktig hvor kostnader genereres og iverksette tiltak, som å redusere Lambda-utkjøringstid, begrense unødvendige invokasjoner eller optimalisere loggingsstrategier.
Eksempel fra praksis
For eksempel oppdaget vi at visse AWS Lambda-funksjoner i et av våre helsesystemprosjekter forbrukte opptil $300 per måned. Ved å analysere CloudWatch-metrikker, optimaliserte vi funksjonene og reduserte kostnadene til bare $20–30—noe som resulterte i besparelser på nær $1,000.
De største kostnadsdriverne vi vanligvis ser er ineffektiv Lambda-utkjøringstid, overflødig logging og uoptimaliserte gjentaksmekanismer.
Hva er AWS CloudWatch?
Amazon CloudWatch er en overvåkings- og observabilitetstjeneste designet for å gi sanntidssynlighet i applikasjoner, infrastruktur og systematferd.
I helsesystemer, hvor flere tjenester, integrasjoner og datastreamer opererer samtidig, fungerer CloudWatch som et sentralisert lag som samler og korrelerer operasjonelle data på tvers av hele systemet.
CloudWatch opererer på tre hovedlag — metrikker, logger og hendelser — som sammen muliggjør full observabilitet av distribuerte systemer.
Det aggregerer tre kjerne typer data:
- Metrikker — ytelsesindikatorer som latens, CPU-bruk, fe率 og forespørselvolum
- Logger — detaljerte opptegnelser av systemhendelser, applikasjonsatferd og feil
- Hendelser — systemendringer, utløserne og automatiserte svar
Dette enhetlige synet lar team oppdage problemer raskere, forstå deres rotårsaker og reagere før de påvirker kliniske arbeidsflyter.
CloudWatch er ikke bare et overvåkingsverktøy, men et operasjonelt kontrollag som muliggjør:
- Sanntidssystemsynlighet på tvers av distribuerte helsetjenesteapplikasjoner
- Proaktiv oppdagelse av problemer gjennom terskler og anomalideteksjon
- Automatiserte svar på systemhendelser (f.eks., skalering, omstarter, varsler)
I komplekse helsemiljøer, hvor systemene inkluderer EHR-plattformer, IoT-enheter, API-er og tredjepart-integrasjoner, er dette nivået av synlighet avgjørende for å opprettholde systempålitelighet og dataintegritet. Som et resultat blir CloudWatch en nøkkelkomponent i helsesektorens observabilitet i moderne skybaserte systemer.
Nøkkelfunksjoner av CloudWatch for Helsevesenet
CloudWatch gir et sett med kjernefunksjoner som støtter observabilitet i helsesektoren, rask hendelsesrespons og operasjonell kontroll i helsesystemer.
Automatiserte varsler og meldinger
Hva det gjør:
CloudWatch utløser varsler når forhåndsdefinerte terskler eller anomalimønstre oppdages, og varsler teamene via integrerte kommunikasjonskanaler.
Hvorfor det er viktig i helsevesenet:
Muliggjør umiddelbar respons på kritiske problemer som API-feil, høy ventetid eller forsøk på uautorisert tilgang før de påvirker kliniske arbeidsflyter eller pasientbehandling.
Eksempel:
For eksempel kan et varsel utløses når feilmengder overstiger en definert terskel eller når forsøk på uautorisert tilgang oppdages, noe som gjør at team kan reagere før sikkerhet eller dataintegritet kompromitteres.
Integrasjon med AWS Lambda
Hva det gjør:
CloudWatch integreres med AWS Lambda for å utløse automatiserte handlinger som svar på systemhendelser, som å prøve på nytt mislykkede prosesser, starte tjenester eller skalere infrastruktur.
Hvorfor det er viktig i helsevesenet:
Støtter automatisert hendelsesrespons, som lar systemer selvreparere uten manuell inngripen. Dette er spesielt viktig i tidssensitive miljøer hvor forsinkelser i respons kan forstyrre pleieleveransen.
Eksempel:
For eksempel, hvis en databehandlingsfunksjon mislykkes, kan CloudWatch automatisk utløse en mekanisme for gjentakelse eller omstart, og sikre at kritiske pasientdata behandles uten manuell inngripen.
AI-drevet anomalideteksjon
Hva det gjør:
CloudWatch bruker maskinlæringsmodeller for å oppdage uvanlige mønstre i systemadferd, selv når ingen faste terskler er definert.
Hvorfor det er viktig i helsevesenet:
Hjelper med å oppdage unormal systemadferd, som uventede topper i API-bruk eller fall i data fra medisinske enheter, noe som muliggjør proaktiv problemløsning før det påvirker pasientbehandlingen.
Eksempel:
For eksempel kan et plutselig fall i innkommende data fra tilkoblede medisinske enheter signalisere enhetsfeil eller tilkoblingsproblemer, noe som lar teamene undersøke før pasientovervåkningen påvirkes.
Hvordan AWS CloudWatch fungerer
CloudWatch fungerer som en kontinuerlig overvåkningssyklus som samler inn, behandler og handler på systemdata i sanntid. Denne prosessen kan representeres som en sløyfe bestående av fire nøkkelstadier:
Innsamle
CloudWatch samler inn metrikker og logger fra AWS-ressurser, applikasjoner og tilkoblede systemer, inkludert servere, API-er, databaser og IoT-enheter.
Overvåk
De innsamlede dataene visualiseres gjennom dashbord, noe som gjør det mulig for team å følge med på systematferd, korrelere metrikker og logger, og identifisere ytelsesproblemer eller avvik.
Handle
Når forhåndsdefinerte terskler overskrides eller uvanlige mønstre oppdages, utløser CloudWatch varsler eller automatiserte reaksjoner, som å skalere infrastrukturen eller starte tjenester på nytt.
Analyser
CloudWatch muliggjør dypere analyse av systematferd ved hjelp av historiske data, høypresisjonsmetrikker, og verktøy som Metric Math for å identifisere trender og optimalisere ytelse.
I henhold til denne flyten muliggjør CloudWatch en fullt automatisert overvåkningsprosess der data kontinuerlig samles inn, analyseres og brukes til å utløse handlinger.
Innen helsesystemer er denne syklusen kritisk fordi den muliggjør automatisk oppdagelse av avvik, som unormal API-latenstid eller feil i databehandling. Disse problemene kan umiddelbart utløse varsler og automatiserte skaleringer eller gjenopprettingshandlinger uten manuell inngripen, og sikre at kliniske systemer forblir responsive og pålitelige. Denne tilnærmingen er essensiell for effektiv overvåkning i helsesystemer og sanntidsvarsling, der umiddelbar respons er nødvendig.
Case Study: AWS CloudWatch i en helsesammenheng
La oss se på hvordan AWS CloudWatch for helseprosjekter ble implementert i et av våre helseprosjekter — en plattform for fjernovervåking av pasienter brukt av klinikker og pasienter.
Prosjektkontekst
- Bygget på AWS-infrastruktur
- Mer enn 500 AWS Lambda-funksjoner
- To plattformer: web (for praktikere) og mobil (for pasienter)
- 20 000+ brukere på tvers av plattformer
- 500+ loggrupper og 1 400+ metrikker overvåket
Dette var et høy-ytelses, sanntidssystem med kontinuerlig databehandling, hvor pasientdata, enhetssignaler og systemhendelser ble behandlet uten avbrudd.
Datainnsamling og visualisering
Vi samler inn store mengder logger, metrikker og hendelser fra flere AWS-tjenester, inkludert:
- API Gateway — forespørselshastigheter, latenstid, feilsvar
- AWS Lambda — eksekveringsvarighet, invokasjonsantall, feilhastigheter
- DynamoDB — lese/skrive kapasitetsbruk, throttling-hendelser
CloudWatch konsoliderer disse dataene i et sentralisert dashbord, som gir sanntidsinnsyn i systematferd.
Dette gjør det mulig for team å raskt identifisere:
- ytelsesflaskehalser
- feilende tjenester
- unormal systematferd
og spore problemer tilbake til deres nøyaktige kilde.
Varslingskonfigurasjon, målinger og hendelser
Vi har konfigurert varsler basert på kritiske systemterskler og sanntidshendelser.
Eksempler på varsler inkluderer:
- Latency-varsler utløst når API-responstiden overskrider definerte terskler (f.eks. >300–500 ms)
- Feilrate-varsler aktivert når feilratene overskrider akseptable nivåer (f.eks. >2–5%)
- Varsler om uautorisert tilgang utløst ved mistenkelige autentiseringsforsøk eller uvanlige tilgangsmønstre
Dessuten kan disse varslene defineres i kode eller konfigureres direkte i CloudWatch.
Målinger og hendelser brukes også til å automatisere systematferd, som for eksempel:
- skalere infrastrukturen under økt lasten
- utløse varsler for driftsteam
- innlede gjenopprettingshandlinger for mislykkede prosesser
Innvirkning
Med denne oppsettet oppnådde systemet:
- Raskere oppdagelse og løsning av ytelsesproblemer
- Redusert nedetid i pasientrettede tjenester
- Forbedret pålitelighet av sanntids databehandling
- Bedre kontroll over infrastrukturens atferd under belastning
Ikke minst sikret overvåkningssystemet at kritiske helsearbeidsflyter forble stabile og responsive, selv under høy belastning og kontinuerlige datastreams.
Eksempler på CloudWatch-bruk i vårt helseprosjekt
La oss ta en nærmere titt på hvordan CloudWatch fungerer innen helseprosjektet vi introduserte tidligere.
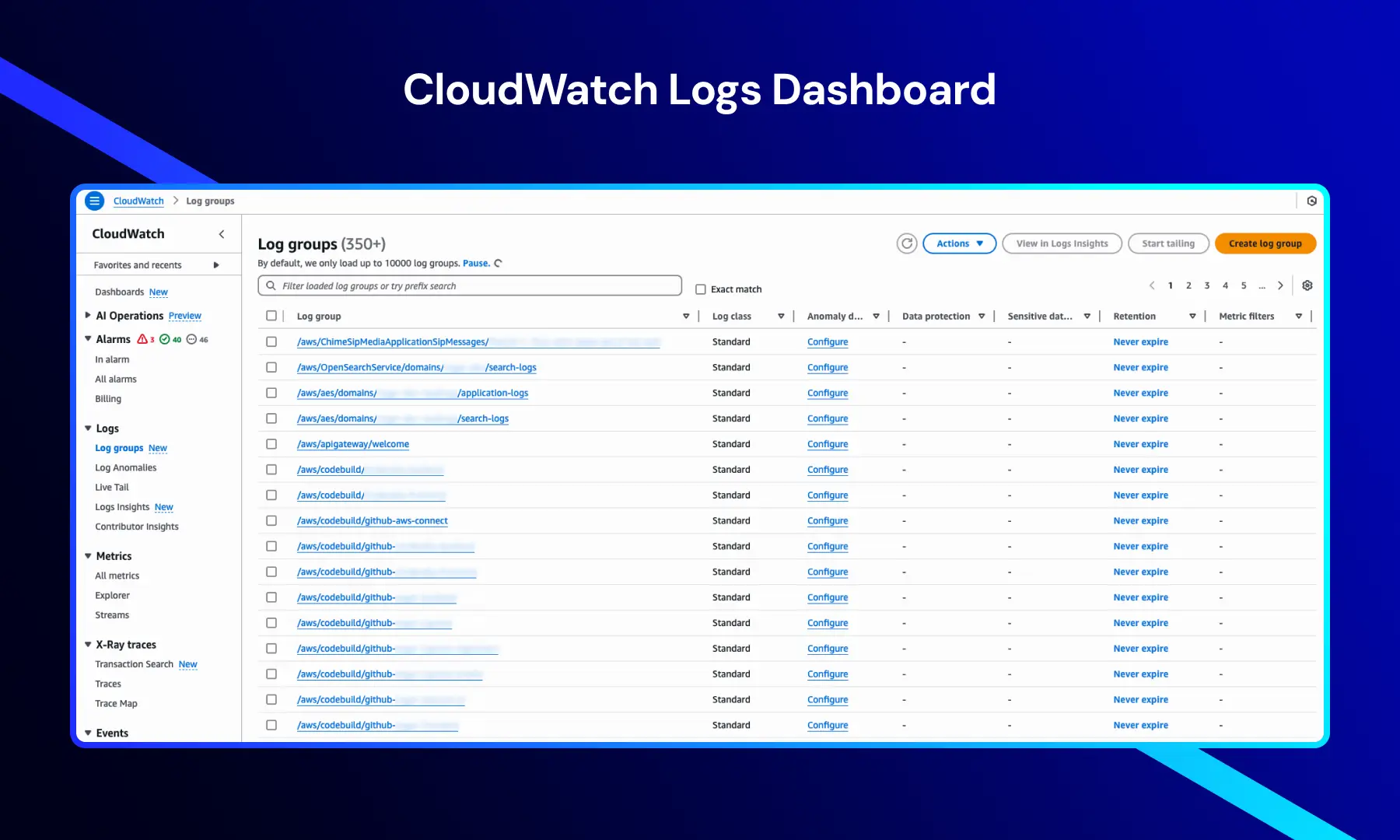
CloudWatch Logs Dashboard
Denne visningen viser loggrupper som organiserer og lagrer logger fra forskjellige AWS-tjenester og ressurser.
Den gir nøkkelinformasjon som:
- Logggruppenavn — logger generert av applikasjoner, infrastruktur og AWS-tjenester
- Loggklasse — vanligvis satt til Standard for standard logghåndtering
- Oppbevaringsinnstillinger — ofte konfigurert til "Aldri utløpe" for langsiktig analyse
- Konfigurasjon av anomalioppdagelse — muliggjør identifisering av uvanlige loggmønstre
Navigasjonsalternativer som Alarmer, Målinger, X-Ray-spor og Hendelser gir tilgang til den komplette overvåkings- og analysemulighetene til CloudWatch.
Denne visningen er avgjørende for sentralisert logghåndtering og effektiv feilsøking på tvers av distribuerte systemer.
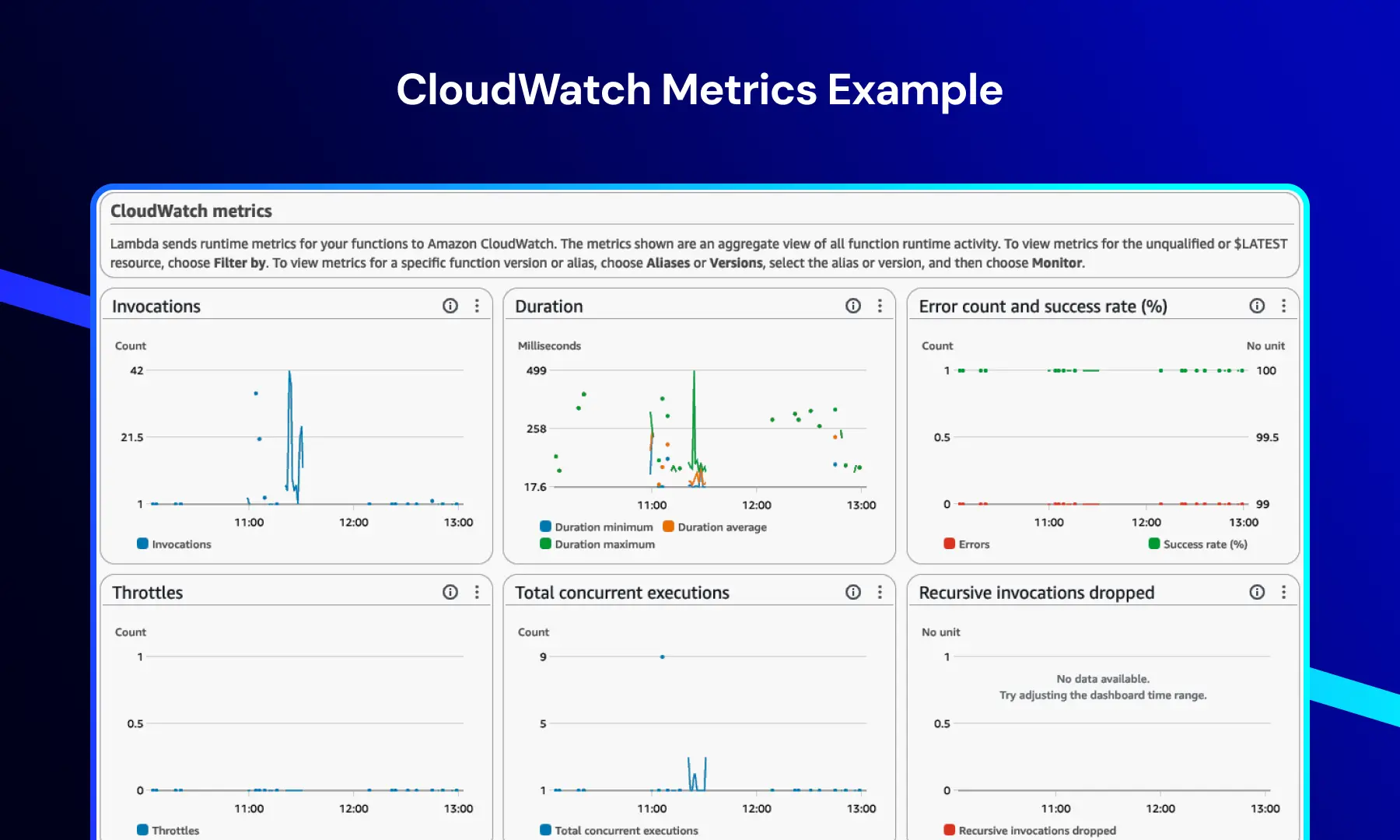
CloudWatch Metrics
Denne dashbordet gir sanntidsinnsikt i system- og applikasjonsytelse.
Det inkluderer typisk:
- Funksjonsinvokasjoner
- Kjøringsvarighet
- Feilrater
- Throttling-hendelser
Dette gjør at team kan overvåke ytelsestrender, oppdage flaskehalser og opprettholde systemstabilitet under belastning.
Lambda Funksjonsmålinger
Dette dashbordet fokuserer på detaljerte ytelsesmålinger for AWS Lambda-funksjoner.
Nøkkelsynspunkter inkluderer:
- De dyreste invokasjonene — identifisere funksjoner med høyest ressursforbruk
- Kjøringsvarighet vs fakturert varighet — forstå kostnadens atferd basert på AWS faktureringsregler
- Tilgang til detaljerte logger — muliggjør rask feilsøking og ytelsesoptimalisering
Dette nivået av synlighet er kritisk for å optimalisere både ytelse og infrastrukturkostnader i hendelsesdrevne helsesystemer.

![Cloud Software Development [AWS].webp](/static/Cloud_Software_Development_AWS_a351611d38.webp)
Fordeler med AWS CloudWatch for Helsevesen
CloudWatch gir helsesystemer den synligheten og kontrollen som kreves for å opprettholde ytelse, pålitelighet og sikkerhet i komplekse, sanntidsmiljøer.
Nøkkelfordeler inkluderer:
Full observabilitet på tvers av systemer
CloudWatch muliggjør end-to-end helsesynlighet på tvers av API-er, databaser, infrastruktur og tilkoblede medisinske enheter, og lar team forstå systemadferd i sanntid og raskt identifisere unormale forhold.
Raskere hendelsesrespons
Automatiserte varsler og sanntidsovervåking reduserer responstiden, noe som hjelper team å oppdage og løse problemer før de påvirker kliniske arbeidsflyter eller pasientbehandling.
Redusert nedetid
Tidlig oppdagelse av anomalier og automatiserte gjenopprettingshandlinger minimerer tjenesteavbrudd i kritiske helsesystemer.
Forbedret operasjonell effektivitet
Klart synlighet inn i systemytelsen lar team optimalisere ressursbruken og opprettholde stabil systemadferd under varierende belastningsforhold.
Forbedret samsvar og sikkerhet
Kontinuerlig overvåking og logging støtter revisjonskrav og hjelper til med å oppdage uautorisert tilgang eller uvanlig systemaktivitet.
Skalerbarhet
CloudWatch skalerer med systemvekst, støtter økende datamengder, brukere og tilkoblede enheter uten tap av synlighet.
Er det mulig å ikke bruke CloudWatch?
Ja, det finnes alternativer til CloudWatch, og i enkelte tilfeller kan de være mer egnet avhengig av systemarkitektur og teampreferanser.
Vanlige alternativer inkluderer:
- Datadog — tilbyr avanserte overvåkingsmuligheter med et sterkt brukergrensesnitt og rike visualiseringsverktøy
- Prometheus + Grafana — åpen kildekode-løsning som gir fleksibel innsamling og visualisering av metrikker, ofte brukt i tilpassede eller multi-sky-miljøer
- Elastic Stack (ELK) — fokusert på sentralisert loggforvaltning og søkefunksjonalitet
- New Relic — gir fullstendig observabilitet med sterkt støtte for overvåking av applikasjonsytelse
Valget avhenger imidlertid i stor grad av hvor tett systemet ditt er integrert med AWS.
Sammenligningsoversikt
| Verktøy | Nøkkelfordel | Ulemper |
|---|---|---|
| Datadog | Bedre UI og brukeropplevelse | Høyere kostnad i stor skala |
| Prometheus | Svart fleksibel og tilpassbar | Kompleks oppsett og vedlikehold |
| CloudWatch | Best egnet for AWS-native systemer | Begrenset fleksibilitet utenfor AWS |
CloudWatch forblir et praktisk valg for AWS-baserte helsesystemer på grunn av sin native integrasjon, lavere driftskostnader og sømløs skalerbarhet.
For team som opererer fullt ut innen AWS, reduserer det behovet for ekstra verktøy og forenkler overvåkingsarkitekturen uten å gå på bekostning av synlighet eller kontroll.
Gjennomføringssteg for AWS CloudWatch
Implementering av CloudWatch i helsesystemer krever ikke bare riktig oppsett, men også en strukturert tilnærming for å unngå vanlige fallgruver som kan påvirke ytelse, kostnader og pålitelighet.
1. Sett opp overvåking
Aktiver CloudWatch for alle relevante AWS-tjenester og definer de viktigste metrikene som reflekterer systemets helse og ytelse.
- Konfigurer overvåking for API-er, databaser, databehandlingstjenester og integrasjoner
- Installer CloudWatch-agenter der det er nødvendig (f.eks. for tilpassede servere)
- Fokuser på kritiske metrikker som latens, feilrater og systemlast
Beste praksis:
Start med et minimalt, men meningsfullt sett med metrikker knyttet til faktiske systemrisikoer (f.eks. API-latens, mislykkede forespørsel, dataversinkelser).
Hva du ikke skal gjøre:
Unngå å spore for mange metrikker fra starten av — dette skaper støy, øker kostnadene og gjør det vanskeligere å identifisere reelle problemer.
2. Konfigurer Dashboards og varsler
Opprett dashboards og varsler som reflekterer reelle driftsprioriteringer snarere enn generiske systemmetrikker.
- Bygg dashboards for nøkkelarbeidsflyter (f.eks., pasientdataflyt, API-ytelse)
- Sett varsler for latens, fe rates, og unormal systematferd
- Definer terskler basert på reell systembruk, ikke antagelser
Beste praksis:
Juster varsler med forretningskritiske scenarier, som forsinket tilgang til pasientjournaler eller mislykket datalevering.
Hva du ikke skal gjøre:
Unngå altfor sensitive varsler eller dårlig definerte terskler — dette fører til varslingstrøtthet og neglisjerte meldinger.
3. Automatiser svar
Bruk CloudWatch-integrasjoner for å automatisere systemreaksjoner på hendelser.
- Utøv AWS Lambda-funksjoner for forsøk, skalering, eller gjenopprettingshandlinger
- Konfigurer automatisk skalering basert på belastning og ytelsesmetrikker
- Integrer varsler med hendelseshåndteringsverktøy
Beste praksis:
Automatiser svar på forutsigbare feil (f.eks. forsøk for midlertidige feil, skalering under trafikkøkninger).
Hva du ikke skal gjøre:
Ikke stol helt på manuell inngripen — i helsevesenet kan forsinkede svar direkte påvirke systemets pålitelighet.
4. Test og optimaliser kontinuerlig
Overvåking er ikke et engangssett — det krever regelmessig testing og optimalisering.
- Valider at varsler utløses korrekt
- Simuler feilsituasjoner (f.eks. API-nedetid, dataverskudd)
- Gå jevnlig gjennom og juster terskler, metrikker og varsel-logikk
Beste praksis:
Finslip kontinuerlig overvåking basert på reelle hendelser og systematferd.
Hva du ikke skal gjøre:
Unngå en "sett og glem"-tilnærming — utdaterte konfigurasjoner overser ofte kritiske problemer eller genererer irrelevante varsler.
Konklusjon
AWS CloudWatch er et praktisk valg for overvåking av helsevesenssystemer i AWS-miljøer, og gir synlighet, varsling og kostnadskontroll som er nødvendig for produksjonsmiljøer.
I komplekse helsearkitekturer, der mange tjenester, integrasjoner og sanntidsdataflyt må operere pålitelig, gjør CloudWatch det mulig for team å opprettholde stabilitet, oppdage problemer tidlig, og svare uten forsinkelse.
Når det implementeres riktig, støtter det full observabilitet, raskere hendelseshåndtering og mer forutsigbar systematferd under belastning.
Etter hvert som helsevesenssystemer fortsetter å skalere og bli mer datadrevne, er det ikke lenger valgfritt å ha en godt definert overvåkings- og varslingsstrategi — det er en kjernekomponent i å bygge pålitelig og vedlikeholdbart programvare.
Hvis du designer eller skalere en helseplattform på AWS, kan en godt konfigurert CloudWatch-oppsett betydelig redusere driftsrisiko og forbedre systemytelsen.
Trenger du hjelp med å implementere CloudWatch i prosjektet ditt innen helsevesen?
Hos JetBase hjelper vi helsepersonell med å designe overvåkingssystemer som går utover grunnleggende oppsett — med fokus på pålitelighet, kostnadseffektivitet og virkelige prestasjoner.
Enten du bygger en ny plattform eller optimaliserer en eksisterende, kan vi hjelpe deg med å sette opp en overvåkningsstrategi som passer din arkitektur og forretningsmål.
Kontakt oss for å diskutere prosjektet ditt eller få en konsultasjon.