Dans cet article, nous allons explorer AWS CloudWatch—un outil de surveillance et de gestion polyvalent que nous recommandons pour les projets de développement en santé. CloudWatch offre une visibilité en temps réel sur l'infrastructure et les applications, permettant des actions rapides pour maintenir la performance et la fiabilité.
Cela est particulièrement important dans les systèmes de santé, qui gèrent des données sensibles des patients, fournissent une surveillance continue et exécutent des applications critiques où même de petites interruptions peuvent impacter les flux de travail cliniques et la disponibilité des données. La surveillance dans les systèmes de santé est essentielle car ces environnements fonctionnent en temps réel, ne laissant aucune place aux retards dans la détection ou la réponse. Cela fait de la surveillance et de l'alerte des systèmes de santé un composant critique d'une architecture système fiable.
L'importance de la surveillance et des alertes en santé
Les systèmes de santé fonctionnent dans des environnements en temps réel où même de petites interruptions peuvent directement impacter les flux de travail cliniques et l'efficacité opérationnelle.
En pratique, les pannes ne ressemblent rarement à une panne complète du système. Au lieu de cela, elles apparaissent comme de petits mais critiques problèmes :
- Un temps d'arrêt de l'API entraîne l'absence d'accès aux Dossiers de Santé Électroniques (DSE), retardant les décisions de diagnostic et de traitement
- Des alertes retardées signifient que des signes vitaux anormaux des patients, tels que le rythme cardiaque ou les niveaux d'oxygène, ne sont pas escaladés à temps
- Des intégrations échouées empêchent les résultats de laboratoire ou les données d'imagerie d'atteindre l'équipe de soins
Même lorsque les systèmes restent techniquement opérationnels, ces problèmes peuvent silencieusement perturber la prestation de soins. Les systèmes de surveillance et d'alerte sont essentiels car ils détectent ces pannes tôt et permettent une réponse rapide. Sans visibilité adéquate, les équipes découvrent souvent les problèmes seulement après qu'ils commencent à affecter les utilisateurs ou les patients.
Un simple retard dans la livraison des alertes (par exemple, 30 à 60 secondes) peut impacter des flux de travail sensibles au temps tels que la surveillance en USI ou les systèmes de réponse d'urgence, où le temps de réaction est crucial.
Une surveillance robuste garantit :
- Un accès continu aux systèmes critiques tels que les DSE, la surveillance à distance des patients et les plateformes de télémédecine
- Une détection précoce des anomalies avant qu'elles ne s'aggravent en pannes plus importantes
- Un flux de données fiable entre les systèmes, surtout dans les environnements intensivement intégrés
Dans le domaine de la santé, la surveillance ne concerne pas seulement la stabilité de l'infrastructure. Il s'agit de maintenir l'intégrité des flux de travail cliniques, où le timing, l'exactitude et la disponibilité des données influencent directement les résultats.
Améliorer la sécurité des patients avec AWS CloudWatch
La surveillance et l'alerte des systèmes de santé jouent un rôle critique dans le maintien de la sécurité des patients en s'assurant que les données sont disponibles, exactes et livrées à temps. En pratique, cela nécessite de suivre des comportements spécifiques du système et de réagir immédiatement aux pannes.
Dossiers de Santé Électroniques (DSE)
Pour les systèmes DSE, un accès continu aux données des patients dépend de la stabilité des services en arrière-plan et des bases de données.
- Ce qui est surveillé : latence de l'API, temps de réponse de la base de données, taux d'erreurs
- Type d'alerte : alertes basées sur des seuils concernant les pics de latence et les augmentations du taux d'erreurs
- Exemples de déclencheurs : le temps de réponse de l'API dépasse les limites définies, les requêtes de la base de données ralentissent ou les taux d'erreurs augmentent au-dessus des niveaux normaux
La surveillance de ces métriques garantit un accès ininterrompu aux dossiers des patients et empêche les retards dans la prise de décision clinique.
Systèmes d'Aide à la Décision Clinique (SADC)
Les plateformes SADC reposent sur un traitement rapide des règles cliniques et un échange de données fluide avec des systèmes externes.
- Ce qui est surveillé : temps de traitement des règles, état d'intégration avec les systèmes de laboratoire, retards d'exécution du système
- Type d'alerte : alertes basées sur des événements et alertes de latence pour un traitement retardé ou échoué
- Exemples de déclencheurs : exécution retardée des règles cliniques, échecs d'appels API aux systèmes de laboratoire, ou données d'entrée manquantes
Des alertes peuvent être déclenchées lorsque les règles cliniques ne sont pas traitées à temps ou lorsque les intégrations échouent, réduisant le risque de recommandations manquées ou de décisions de traitement incorrectes.
Surveillance à distance des patients (RPM)
Les systèmes RPM dépendent d'un flux de données continu provenant d'appareils médicaux et d'une analyse en temps réel des signes vitaux des patients.
- Ce qui est surveillé : connectivité des appareils, taux d'ingestion des données, seuils vitaux anormaux
- Type d'alerte : alertes en temps réel pour données manquantes ou métriques anormales des patients
- Exemples de déclencheurs : déconnexions d'appareils, baisse de la fréquence de transmission des données, ou signes vitaux dépassant des seuils prédéfinis
Ces alertes garantissent que les équipes de soins sont immédiatement informées des problèmes techniques et des risques potentiels pour les patients, permettant une intervention plus rapide.
Optimisation des coûts et efficacité avec AWS CloudWatch
Les coûts du cloud peuvent croître rapidement dans les environnements de santé s'ils ne sont pas gérés. Dans les environnements de santé AWS CloudWatch, l'optimisation des coûts dépend de la visibilité sur des moteurs de coûts spécifiques plutôt que sur la performance générale du système.
En pratique, cela signifie identifier où les coûts sont générés et optimiser le comportement du système en fonction des modèles d'utilisation réels.
Les principaux facteurs de coûts dans les systèmes de santé basés sur AWS incluent :
- Durée d'exécution de Lambda — des temps d'exécution plus longs augmentent directement les coûts de calcul
- Nombre d'invocations — des déclencheurs à haute fréquence (surtout dans les systèmes basés sur des événements) peuvent augmenter significativement l'utilisation totale
- Volume des logs — des journaux excessifs ou non structurés entraînent des coûts de stockage et d'ingestion élevés
- Stockage des métriques — de grands volumes de métriques personnalisées, surtout avec une haute granularité, peuvent augmenter les dépenses de surveillance
CloudWatch fournit des informations détaillées sur ces aspects, permettant aux équipes de suivre les modèles d'utilisation et d'effectuer des optimisations ciblées.
Au lieu d'analyser de manière globale le comportement du système, les équipes peuvent identifier exactement où les coûts sont générés et agir, comme réduire le temps d'exécution de Lambda, limiter les invocations inutiles, ou optimiser les stratégies de journalisation.
Exemple pratique
Par exemple, nous avons découvert que certaines fonctions AWS Lambda dans l'un de nos projets de santé consommaient jusqu'à 300 $ par mois. En analysant les métriques de CloudWatch, nous avons optimisé les fonctions et réduit les coûts à seulement 20-30 $ — entraînant des économies de près de 1 000 $.
Les principaux moteurs de coûts que nous observons généralement sont le temps d'exécution inefficace de Lambda, une journalisation excessive et des mécanismes de réessai non optimisés.
Qu'est-ce qu'AWS CloudWatch ?
Amazon CloudWatch est un service de surveillance et d'observabilité conçu pour fournir une visibilité en temps réel sur les applications, l'infrastructure et le comportement des systèmes.
Dans les systèmes de santé, où plusieurs services, intégrations et flux de données fonctionnent simultanément, CloudWatch agit comme une couche centralisée qui collecte et corrèle les données opérationnelles à travers tout le système.
CloudWatch fonctionne sur trois couches principales — métriques, journaux et événements — qui ensemble permettent une pleine observabilité des systèmes distribués.
Il agrège trois types de données essentielles :
- Métriques — indicateurs de performance tels que la latence, l'utilisation du CPU, les taux d'erreur et le volume des requêtes
- Journaux — enregistrements détaillés des événements système, du comportement des applications et des erreurs
- Événements — changements système, déclencheurs et réponses automatiques
Cette vue unifiée permet aux équipes de détecter les problèmes plus rapidement, de comprendre leur cause profonde et de réagir avant qu'ils n'impactent les flux de travail cliniques.
CloudWatch n'est pas qu'un simple outil de surveillance mais une couche de contrôle opérationnel qui permet :
- Une visibilité système en temps réel à travers des applications de santé distribuées
- Une détection proactive des problèmes grâce à des seuils et à la détection d'anomalies
- Des réponses automatisées aux événements système (par exemple., dimensionnement, redémarrages, notifications)
Dans des environnements de santé complexes, où les systèmes incluent des plateformes EHR, des dispositifs IoT, des API et des intégrations tierces, ce niveau de visibilité est essentiel pour maintenir la fiabilité des systèmes et l'intégrité des données. En conséquence, CloudWatch devient un composant clé de l'observation des soins de santé dans les systèmes modernes basés sur le cloud.
Caractéristiques clés de CloudWatch pour la santé
CloudWatch fournit un ensemble de fonctionnalités essentielles qui soutiennent l'observation des soins de santé, la réponse rapide aux incidents et le contrôle opérationnel dans les systèmes de santé.
Alerte et notifications automatisées
Ce qu'il fait :
CloudWatch déclenche des alertes lorsque des seuils prédéfinis ou des modèles d'anomalie sont détectés, notifiant les équipes via des canaux de communication intégrés.
Pourquoi c'est important dans le domaine de la santé :
Permet une réaction immédiate aux problèmes critiques tels que les échecs d'API, la forte latence ou les tentatives d'accès non autorisées avant qu'ils n'affectent les flux de travail cliniques ou les soins aux patients.
Exemple :
Par exemple, une alerte peut être déclenchée lorsque les taux d'erreur dépassent un seuil défini ou lorsque des tentatives d'accès non autorisées sont détectées, permettant aux équipes de réagir avant que la sécurité ou l'intégrité des données ne soit compromise.
Intégration avec AWS Lambda
Ce qu'il fait :
CloudWatch s'intègre à AWS Lambda pour déclencher des actions automatisées en réponse à des événements système, tels que la réexécution de processus échoués, le redémarrage de services ou l'extension de l'infrastructure.
Pourquoi c'est important dans le domaine de la santé :
Soutient la réponse automatisée aux incidents, permettant aux systèmes de se réparer eux-mêmes sans intervention manuelle. Cela est particulièrement important dans des environnements sensibles au temps où les retards dans la réponse peuvent perturber la fourniture de soins.
Exemple :
Par exemple, si une fonction de traitement des données échoue, CloudWatch peut automatiquement déclencher un mécanisme de réessai ou de redémarrage, garantissant que les données critiques des patients sont traitées sans intervention manuelle.
Détection d'anomalies pilotée par l'IA
Ce qu'il fait :
CloudWatch utilise des modèles d'apprentissage automatique pour détecter des modèles inhabituels dans le comportement du système, même lorsqu'aucun seuil fixe n'est défini.
Pourquoi c'est important dans le domaine de la santé :
Aide à détecter un comportement anormal du système, tel que des pics inattendus dans l'utilisation des API ou des baisses de données provenant d'appareils médicaux, permettant une résolution proactive des problèmes avant qu'ils n'affectent les soins aux patients.
Exemple :
Par exemple, une chute soudaine des données entrantes provenant d'appareils médicaux connectés peut signaler une défaillance de l'appareil ou des problèmes de connectivité, permettant aux équipes d'enquêter avant que la surveillance des patients ne soit affectée.
Comment fonctionne AWS CloudWatch
CloudWatch fonctionne comme un cycle de surveillance continue qui collecte, traite et agit sur les données du système en temps réel. Ce processus peut être représenté comme une boucle composée de quatre étapes clés :
Collecter
CloudWatch recueille des métriques et des journaux provenant des ressources AWS, des applications et des systèmes connectés, y compris des serveurs, des API, des bases de données et des appareils IoT.
Surveiller
Les données collectées sont visualisées à travers des tableaux de bord, permettant aux équipes de suivre le comportement des systèmes, de corréler les métriques et les journaux, et d'identifier les problèmes de performance ou les anomalies.
Agir
Lorsque des seuils prédéfinis sont dépassés ou que des modèles inhabituels sont détectés, CloudWatch déclenche des alertes ou des réponses automatisées, telles que la mise à l'échelle de l'infrastructure ou le redémarrage des services.
Analyser
CloudWatch permet une analyse plus approfondie du comportement des systèmes en utilisant des données historiques, des métriques de haute résolution et des outils comme Metric Math pour identifier les tendances et optimiser la performance.
Selon ce flux, CloudWatch permet un processus de surveillance entièrement automatisé où les données sont continuellement collectées, analysées et utilisées pour déclencher des actions.
Dans les systèmes de santé, ce cycle est critique car il permet la détection automatique des anomalies, telles que la latence API anormale ou les pannes dans le traitement des données. Ces problèmes peuvent immédiatement déclencher des alertes et des actions de mise à l'échelle ou de récupération automatisées sans intervention manuelle, garantissant que les systèmes cliniques restent réactifs et fiables. Cette approche est essentielle pour une surveillance efficace dans les systèmes de santé et un alertage en temps réel, où une réponse immédiate est requise.
étude de cas : AWS CloudWatch dans un contexte de santé
Examinons comment AWS CloudWatch pour les projets de santé a été mis en œuvre dans l'un de nos projets de santé — une plateforme de surveillance des patients à distance utilisée par des cliniques et des patients.
Contexte du projet
- Construit sur l'infrastructure AWS
- Plus de 500 fonctions AWS Lambda
- Deux plateformes : web (pour les praticiens) et mobile (pour les patients)
- Plus de 20 000 utilisateurs sur les plateformes
- Plus de 500 groupes de journaux et plus de 1 400 métriques surveillées
C'était un système à fort enjeu et en temps réel avec un traitement continu des données, où les données des patients, les signaux des appareils et les événements système étaient traités sans interruption.
Collecte et visualisation des données
Nous collectons de grands volumes de journaux, de métriques et d'événements provenant de plusieurs services AWS, y compris :
- API Gateway — taux de demandes, latence, réponses d'erreur
- AWS Lambda — durée d'exécution, nombre d'invocations, taux d'erreur
- DynamoDB — utilisation de la capacité de lecture/écriture, événements de throttling
CloudWatch consolide ces données dans un tableau de bord centralisé, fournissant une visibilité en temps réel sur le comportement des systèmes.
Cela permet aux équipes d'identifier rapidement :
- les goulets d'étranglement de performance
- les services défaillants
- le comportement anormal du système
et de retracer les problèmes jusqu'à leur source exacte.
Configuration des alertes, métriques et événements
Nous avons configuré des alertes basées sur des seuils critiques du système et des événements en temps réel.
Exemples d'alertes incluent :
- Alertes de latence déclenchées lorsque le temps de réponse de l'API dépasse les seuils définis (par exemple, >300–500 ms)
- Alertes de taux d'erreur activées lorsque les taux d'erreur dépassent des niveaux acceptables (par exemple, >2–5%)
- Alertes d'accès non autorisé déclenchées lors de tentatives d'authentification suspectes ou de schémas d'accès inhabituels
Ces alertes peuvent être définies dans le code ou configurées directement dans CloudWatch.
Les métriques et événements sont également utilisés pour automatiser le comportement du système, tel que :
- scaler l'infrastructure sous charge accrue
- déclencher des notifications pour les équipes opérationnelles
- initier des actions de récupération pour les processus échoués
Impact
Avec cette configuration, le système a atteint :
- Une détection et une résolution plus rapides des problèmes de performance
- Une réduction du temps d'arrêt des services destinés aux patients
- Une fiabilité améliorée du traitement des données en temps réel
- Un meilleur contrôle sur le comportement de l'infrastructure sous charge
Ce qui est le plus important, c'est que le système de surveillance a garanti que les flux de travail critiques en matière de santé demeurent stables et réactifs, même sous une forte charge et des flux de données continus.
Exemples d'utilisation de CloudWatch dans notre projet de santé
Examinons de plus près comment CloudWatch fonctionne au sein du projet de santé que nous avons présenté précédemment.
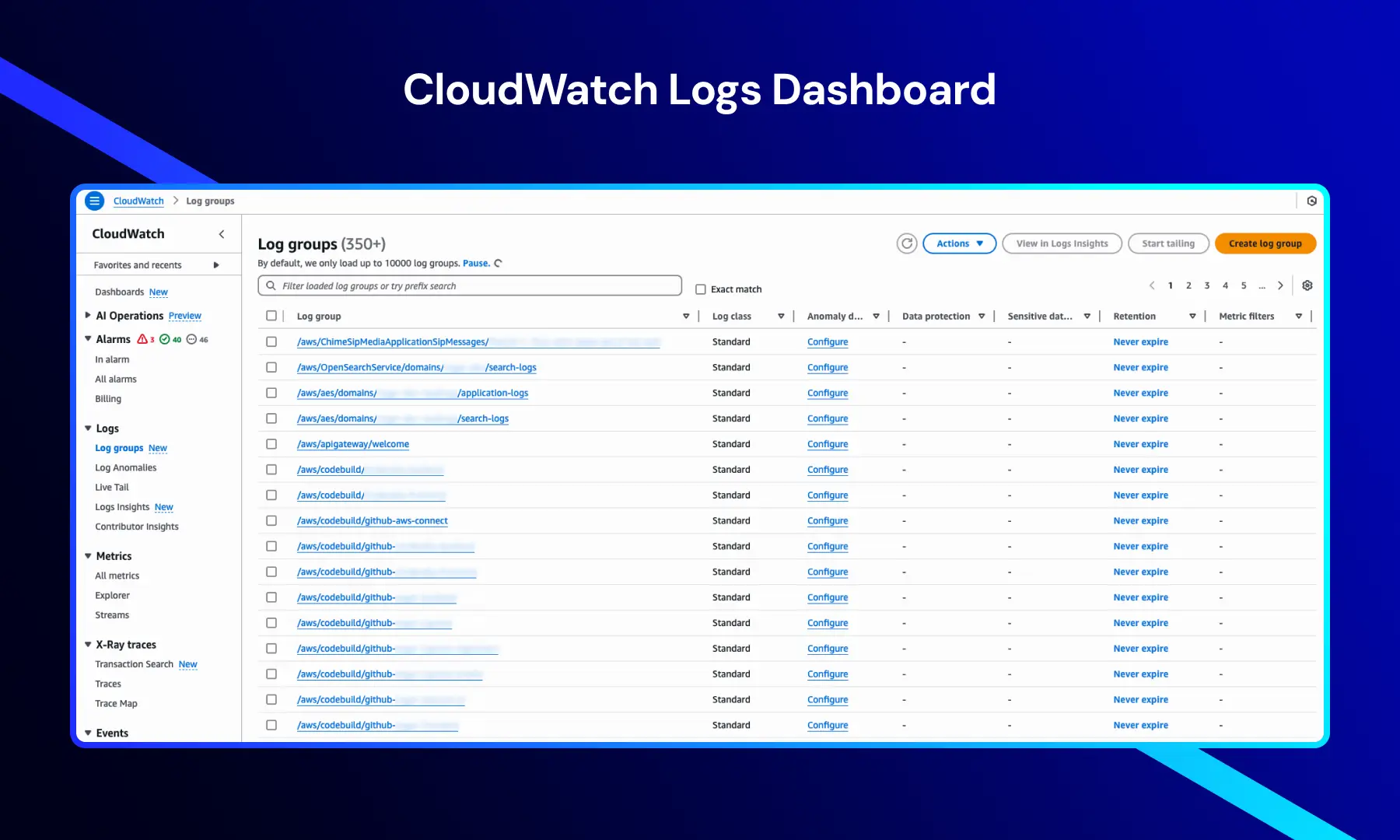
Tableau de bord des journaux CloudWatch
Cette vue affiche des groupes de journaux qui organisent et stockent les journaux provenant de différents services et ressources AWS.
Elle fournit des informations clés telles que :
- Noms des groupes de journaux — journaux générés par des applications, l'infrastructure et des services AWS
- Classe de journal — généralement configurée sur Standard pour la gestion par défaut des journaux
- Paramètres de conservation — souvent configurés pour « Ne jamais expirer » pour une analyse à long terme
- Configuration de détection d'anomalies — permettant d'identifier des schémas de journaux inhabituels
Les options de navigation telles que Alarmes, Métriques, traces X-Ray et Événements fournissent un accès aux capacités complètes de surveillance et d'analyse de CloudWatch.
Cette vue est essentielle pour la gestion centralisée des journaux et le dépannage efficace à travers des systèmes distribués.
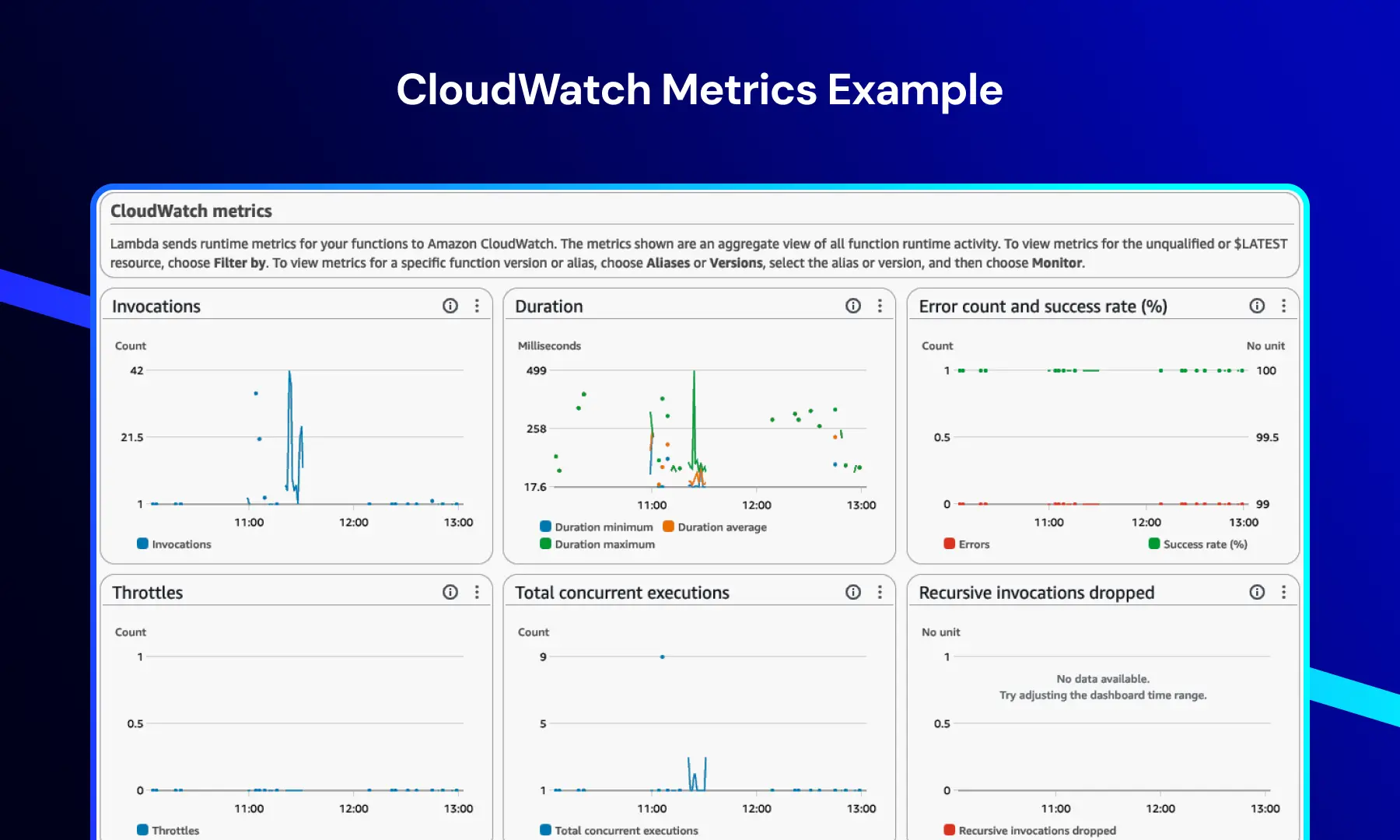
Métriques CloudWatch
Ce tableau de bord fournit des informations en temps réel sur la performance du système et de l'application.
Il comprend généralement :
- Appels de fonction
- Durée d'exécution
- Taux d'erreur
- Événements de limitation
Cela permet aux équipes de surveiller les tendances de performance, de détecter les goulets d'étranglement et de maintenir la stabilité du système sous charge.
Métriques de fonction Lambda
Ce tableau de bord se concentre sur des métriques de performance détaillées pour les fonctions AWS Lambda.
Les principaux éléments à retenir comprennent :
- Appels les plus coûteux — identification des fonctions ayant la plus forte consommation de ressources
- Durée d'exécution vs durée facturée — compréhension du comportement des coûts basé sur les règles de facturation AWS
- Accès aux journaux détaillés — permettant un débogage rapide et une optimisation de la performance
Ce niveau de visibilité est essentiel pour optimiser à la fois la performance et les coûts d'infrastructure dans les systèmes de santé orientés événements.

![Cloud Software Development [AWS].webp](/static/Cloud_Software_Development_AWS_a351611d38.webp)
Avantages d'AWS CloudWatch pour la santé
CloudWatch fournit aux systèmes de santé la visibilité et le contrôle nécessaires pour maintenir performance, fiabilité et sécurité dans des environnements complexes et en temps réel.
Les principaux avantages comprennent :
Observabilité complète à travers les systèmes
CloudWatch permet une observabilité de bout en bout dans les soins de santé à travers les API, bases de données, infrastructure et dispositifs médicaux connectés, permettant aux équipes de comprendre le comportement du système en temps réel et d'identifier rapidement les anomalies.
Réponse aux incidents plus rapide
Des alertes automatiques et une surveillance en temps réel réduisent le temps de réaction, aidant les équipes à détecter et résoudre les problèmes avant qu'ils n'impactent les flux de travail cliniques ou les soins aux patients.
Temps d'arrêt réduit
La détection précoce des anomalies et des actions de récupération automatisées minimisent les interruptions de service dans les systèmes de santé critiques.
Amélioration de l'efficacité opérationnelle
Une visibilité claire sur la performance du système permet aux équipes d'optimiser l'utilisation des ressources et de maintenir un comportement stable du système dans des conditions de charge variées.
Conformité et sécurité améliorées
La surveillance continue et la journalisation soutiennent les exigences d'audit et aident à détecter les accès non autorisés ou les activités système inhabituelles.
Scalabilité
CloudWatch s'adapte à la croissance du système, prenant en charge des volumes de données, des utilisateurs et des dispositifs connectés croissants sans perte de visibilité.
Est-il possible de ne pas utiliser CloudWatch ?
Oui, des alternatives à CloudWatch existent, et dans certains cas, elles peuvent être plus adaptées en fonction de l'architecture du système et des préférences de l'équipe.
Les alternatives courantes incluent :
- Datadog — offre des capacités de surveillance avancées avec une interface utilisateur solide et des outils de visualisation riches
- Prometheus + Grafana — solution open source qui fournit une collecte et une visualisation flexibles des métriques, souvent utilisée dans des environnements personnalisés ou multi-cloud
- Elastic Stack (ELK) — axé sur la gestion centralisée des journaux et les capacités de recherche
- New Relic — fournit une observabilité complète avec un support fort pour la surveillance des performances des applications
Cependant, le choix dépend largement de l'intégration de votre système avec AWS.
Aperçu de la comparaison
| Outil | Avantage clé | Compromis |
|---|---|---|
| Datadog | Meilleure interface utilisateur et expérience utilisateur | Coût plus élevé à grande échelle |
| Prometheus | Très flexible et personnalisable | Installation et maintenance complexes |
| CloudWatch | Meilleure adaptation pour les systèmes natifs AWS | Flexibilité limitée en dehors d'AWS |
CloudWatch reste un choix pratique pour les systèmes de santé basés sur AWS en raison de son intégration native, de ses frais d'exploitation réduits et de sa montée en charge transparente.
Pour les équipes opérant entièrement au sein d'AWS, cela réduit le besoin d'outils supplémentaires et simplifie l'architecture de surveillance sans compromettre la visibilité ou le contrôle.
Étapes de mise en œuvre pour AWS CloudWatch
La mise en œuvre de CloudWatch dans les systèmes de santé nécessite non seulement une configuration appropriée, mais également une approche structurée pour éviter les pièges courants qui peuvent impacter la performance, les coûts et la fiabilité.
1. Mettre en place la surveillance
Activez CloudWatch pour tous les services AWS pertinents et définissez les métriques clés qui reflètent la santé et les performances du système.
- Configurez la surveillance pour les APIs, les bases de données, les services de calcul et les intégrations
- Installez les agents CloudWatch là où cela est nécessaire (par exemple, pour des serveurs personnalisés)
- Concentrez-vous sur des métriques critiques telles que la latence, les taux d'erreur et la charge système
Meilleure pratique :
Commencez par un ensemble minimal mais significatif de métriques liées à de réels risques du système (par exemple, latence des API, demandes échouées, retards de données).
Ce qu'il ne faut pas faire :
Évitez de suivre trop de métriques dès le départ — cela crée du bruit, augmente les coûts et complique l'identification des véritables problèmes.
2. Configurer des tableaux de bord et des alertes
Créez des tableaux de bord et des alertes qui reflètent de vraies priorités opérationnelles plutôt que des métriques système génériques.
- Construisez des tableaux de bord pour des flux de travail clés (par exemple., flux de données des patients, performance de l'API)
- Définir des alertes pour la latence, les taux d'erreur et le comportement anormal du système
- Définir des seuils basés sur l'utilisation réelle du système, et non sur des hypothèses
Meilleure pratique :
Aligner les alertes avec des scénarios critiques pour l'entreprise, tels que l'accès retardé aux dossiers des patients ou l'échec de la livraison des données.
Ce qu'il ne faut pas faire :
Évitez les alertes trop sensibles ou les seuils mal définis — cela entraîne une fatigue d'alerte et des notifications ignorées.
3. Automatiser les réponses
Utilisez les intégrations CloudWatch pour automatiser les réactions du système aux incidents.
- Déclencher des fonctions AWS Lambda pour des tentatives, une mise à l'échelle ou des actions de récupération
- Configurer l'auto-scaling en fonction de la charge et des métriques de performance
- Intégrer les notifications avec des outils de gestion des incidents
Meilleure pratique :
Automatisez les réponses pour les pannes prévisibles (par exemple, des tentatives en cas d'erreurs transitoires, mise à l'échelle lors de pics de trafic).
Ce qu'il ne faut pas faire :
Ne pas compter entièrement sur une intervention manuelle — dans les systèmes de santé, des réponses retardées peuvent directement impacter la fiabilité du système.
4. Tester et optimiser en continu
La surveillance n'est pas une configuration unique — elle nécessite des tests et des optimisations réguliers.
- Vérifiez que les alertes se déclenchent correctement
- Simulez des scénarios de panne (par exemple, temps d'arrêt de l'API, retards de données)
- Révisez et ajustez régulièrement les seuils, les métriques et la logique d'alerte
Meilleure pratique :
Raffinez continuellement la surveillance en fonction des incidents réels et du comportement du système.
Ce qu'il ne faut pas faire :
Évitez une approche de « configurer et oublier » — des configurations obsolètes manquent souvent des problèmes critiques ou génèrent des alertes non pertinentes.
Conclusion
AWS CloudWatch est un choix pratique pour la surveillance des systèmes de santé dans les environnements AWS, fournissant la visibilité, l'alerte et le contrôle des coûts nécessaires pour les environnements de production.
Dans des architectures de santé complexes, où plusieurs services, intégrations et flux de données en temps réel doivent fonctionner de manière fiable, CloudWatch permet aux équipes de maintenir la stabilité, de détecter les problèmes tôt et de réagir sans délai.
Lorsqu'il est mis en œuvre correctement, il soutient une observabilité complète, une réponse aux incidents plus rapide et un comportement du système plus prévisible sous charge.
Alors que les systèmes de santé continuent de se développer et de devenir plus axés sur les données, avoir une stratégie de surveillance et d'alerte bien définie n'est plus une option — c'est une partie essentielle de la construction d'un logiciel fiable et maintenable.
Si vous concevez ou évoluez une plateforme de santé sur AWS, une configuration CloudWatch bien conçue peut réduire significativement les risques opérationnels et améliorer la performance du système.
Besoin d'aide pour mettre en œuvre CloudWatch dans votre projet de santé ?
Chez JetBase, nous aidons les équipes de santé à concevoir des systèmes de surveillance qui vont au-delà de la configuration de base — en se concentrant sur la fiabilité, l'efficacité des coûts et la performance dans le monde réel.
Que vous construisiez une nouvelle plateforme ou que vous optimisiez une plateforme existante, nous pouvons vous aider à mettre en place une stratégie de surveillance qui correspond à votre architecture et à vos objectifs commerciaux.
Contactez-nous pour discuter de votre projet ou obtenir une consultation.