In diesem Artikel werden wir AWS CloudWatch – ein vielseitiges Überwachungs- und Verwaltungstool – erkunden, das wir für Gesundheitsentwicklungsprojekte empfehlen. CloudWatch bietet Echtzeit-Transparenz für Infrastruktur und Anwendungen und ermöglicht zeitgerechte Maßnahmen zur Aufrechterhaltung von Leistung und Zuverlässigkeit.
Dies ist besonders wichtig in Gesundheitssystemen, die mit sensiblen Patientendaten umgehen, kontinuierliche Überwachung bieten und kritische Anwendungen betreiben, bei denen selbst geringfügige Störungen klinische Arbeitsabläufe und die Verfügbarkeit von Daten beeinträchtigen können. Die Überwachung in Gesundheitssystemen ist unerlässlich, da diese Umgebungen in Echtzeit arbeiten und keinen Raum für Verzögerungen bei der Erkennung oder Reaktion lassen. Dies macht die Überwachung und Alarmierung von Gesundheitssystemen zu einem kritischen Bestandteil einer zuverlässigen Systemarchitektur.
Die Bedeutung von Überwachung und Alarmen im Gesundheitswesen
Gesundheitssysteme arbeiten in Echtzeitumgebungen, in denen selbst geringfügige Störungen direkte Auswirkungen auf klinische Arbeitsabläufe und die betriebliche Effizienz haben können.
In der Praxis sehen sich Ausfälle selten als vollständiger Systemausfall dar. Stattdessen erscheinen sie als kleine, aber kritische Probleme:
- API-Ausfall führt zu keinem Zugang zu Elektronischen Gesundheitsakten (EHR), was Diagnosen und Behandlungsentscheidungen verzögert
- Verzögerte Alarme bedeuten, dass abnormale Vitalwerte bei Patienten, wie Herzfrequenz oder Sauerstoffsättigung, nicht rechtzeitig eskaliert werden
- Fehlgeschlagene Integrationen verhindern, dass Laborergebnisse oder Bilddaten das Pflege-Team erreichen
Selbst wenn Systeme technisch funktionsfähig bleiben, können diese Probleme die Versorgung leise stören. Überwachungs- und Alarmsysteme sind unerlässlich, da sie diese Ausfälle frühzeitig erkennen und eine schnelle Reaktion ermöglichen. Ohne die richtige Sichtbarkeit entdecken Teams Probleme oft erst, nachdem sie die Benutzer oder Patienten betreffen.
Selbst eine kurze Verzögerung bei der Alarmzustellung (zum Beispiel 30–60 Sekunden) kann sich auf zeitkritische Arbeitsabläufe, wie die Überwachung auf der Intensivstation oder Notfallreaktionssysteme, auswirken, bei denen die Reaktionszeit entscheidend ist.
Robuste Überwachung gewährleistet:
- Kontinuierlicher Zugang zu kritischen Systemen wie EHR, Fernüberwachung von Patienten und Telemedizinplattformen
- Früherkennung von Anomalien, bevor sie sich zu größeren Ausfällen entwickeln
- Zuverlässiger Datenfluss zwischen Systemen, insbesondere in integrationsintensiven Umgebungen
Im Gesundheitswesen geht es bei der Überwachung nicht nur um die Stabilität der Infrastruktur. Es geht darum, die Integrität klinischer Arbeitsabläufe zu wahren, bei denen Zeit, Genauigkeit und Datenverfügbarkeit direkt die Ergebnisse beeinflussen.
Die Patientensicherheit mit AWS CloudWatch verbessern
Die Überwachung und Alarmierung von Gesundheitssystemen spielt eine entscheidende Rolle bei der Aufrechterhaltung der Patientensicherheit, indem sichergestellt wird, dass Daten verfügbar, genau und pünktlich bereitgestellt werden. In der Praxis erfordert dies die Nachverfolgung spezifischer Systemverhaltensweisen und die sofortige Reaktion auf Ausfälle.
Elektronische Gesundheitsakten (EHR)
Für EHR-Systeme hängt der kontinuierliche Zugang zu Patientendaten von der Stabilität der Backend-Dienste und Datenbanken ab.
- Was überwacht wird: API-Latenz, Reaktionszeit der Datenbank, Fehlerquoten
- Art des Alarms: Schwellenwertbasierte Alarme bei Latenzspitzen und Anstiegen der Fehlerquote
- Beispielauslöser: API-Reaktionszeit überschreitet definierte Grenzen, Datenbankabfragen werden langsamer oder die Fehlerquote steigt über normale Level
Die Überwachung dieser Metriken gewährleistet einen ununterbrochenen Zugriff auf Patientenakten und verhindert Verzögerungen bei klinischen Entscheidungsfindungen.
Klinische Entscheidungsunterstützungssysteme (CDSS)
CDSS-Plattformen sind auf die zeitnahe Verarbeitung klinischer Regeln und den nahtlosen Datenaustausch mit externen Systemen angewiesen.
- Was überwacht wird: Regelverarbeitungszeit, Integrationsstatus mit Laborsystemen, Ausführungsverzögerungen des Systems
- Art des Alarms: Ereignisbasiertes und Latenzalarm für verzögerte oder fehlgeschlagene Verarbeitung
- Beispielauslöser: Verzögerte Ausführung klinischer Regeln, fehlgeschlagene API-Aufrufe an Laborsysteme oder fehlende Eingabedaten
Alarme können ausgelöst werden, wenn klinische Regeln nicht rechtzeitig verarbeitet werden oder wenn Integrationen fehlschlagen, wodurch das Risiko verpasster Empfehlungen oder falscher Behandlungsentscheidungen verringert wird.
Fernpatientenüberwachung (RPM)
RPM-Systeme sind auf einen kontinuierlichen Datenfluss von Medizinprodukten und die Echtzeitanalyse der Vitalzeichen der Patienten angewiesen.
- Was überwacht wird: Geräteverbindung, Datenaufnahmegeschwindigkeit, abnormale Vitalgrenzen
- Art des Alarms: Echtzeitalarme für fehlende Daten oder abnormale Patientenmetriken
- Beispielauslöser: Gerätestrennung, Rückgang der Datenübertragungsfrequenz oder Vitalzeichen überschreiten festgelegte Grenzen
Diese Alarme stellen sicher, dass Pflege-Teams sofort über technische Probleme und potenzielle Patientenrisiken informiert werden, was schnellere Interventionen ermöglicht.
Kostenoptimierung und Effizienz mit AWS CloudWatch
Die Cloud-Kosten können in Gesundheitsumgebungen schnell steigen, wenn sie nicht verwaltet werden. In AWS CloudWatch Gesundheitsumgebungen hängt die Kostenoptimierung von der Sichtbarkeit spezifischer Kostentreiber und nicht von der allgemeinen Systemleistung ab.
In der Praxis bedeutet dies, herauszufinden, wo Kosten entstehen und das Systemverhalten basierend auf realen Nutzungsmustern zu optimieren.
Die häufigsten Kostenfaktoren in auf AWS basierenden Gesundheitssystemen sind:
- Dauer der Lambda-Ausführung — längere Ausführungszeiten erhöhen direkt die Compute-Kosten
- Anzahl der Aufrufe — hochfrequente Trigger (insbesondere in ereignisgesteuerten Systemen) können die gesamte Nutzung erheblich erhöhen
- Protokollvolumen — übermäßiges oder unstrukturiertes Logging führt zu hohen Speicher- und Eingabekosten
- Metrik-Speicherung — große Mengen an benutzerdefinierten Metriken, insbesondere mit hoher Granularität, können die Überwachungskosten erhöhen
CloudWatch bietet detaillierte Einblicke in diese Bereiche, sodass Teams Nutzungsmuster verfolgen und gezielte Optimierungen vornehmen können.
Anstatt das Systemverhalten allgemein zu analysieren, können Teams genau identifizieren, wo Kosten entstehen, und Maßnahmen ergreifen, wie z. B. die Reduzierung der Lambda-Ausführungszeit, die Begrenzung unnötiger Aufrufe oder die Optimierung von Logging-Strategien.
Beispiel aus der Praxis
Zum Beispiel haben wir entdeckt, dass bestimmte AWS Lambda-Funktionen in einem unserer Gesundheitsprojekte bis zu 300 USD pro Monat verbraucht haben. Durch die Analyse von CloudWatch-Metriken optimierten wir die Funktionen und reduzierten die Kosten auf nur 20–30 USD — was zu Einsparungen von fast 1.000 USD führte.
Die größten Kostenfaktoren, die wir typischerweise sehen, sind ineffiziente Lambda-Ausführungszeiten, übermäßiges Logging und nicht optimierte Retry-Mechanismen.
Was ist AWS CloudWatch?
Amazon CloudWatch ist ein Überwachungs- und Observabilitätsdienst, der entwickelt wurde, um Echtzeiteinblicke in Anwendungen, Infrastrukturen und Systemverhalten zu bieten.
In Gesundheitssystemen, in denen mehrere Dienste, Integrationen und Datenflüsse gleichzeitig arbeiten, fungiert CloudWatch als zentrale Schicht, die Betriebsdaten im gesamten System sammelt und korreliert.
CloudWatch arbeitet auf drei Hauptschichten — Metriken, Protokolle und Ereignisse — die zusammen vollständige Observabilität verteilter Systeme ermöglichen.
Es aggregiert drei zentrale Datentypen:
- Metriken — Leistungsindikatoren wie Latenz, CPU-Auslastung, Fehlerraten und Anfragevolumen
- Protokolle — detaillierte Aufzeichnungen von Systemereignissen, Anwendungsverhalten und Fehlern
- Ereignisse — Systemänderungen, Trigger und automatisierte Reaktionen
Diese einheitliche Ansicht ermöglicht es Teams, Probleme schneller zu erkennen, ihre Ursachen zu verstehen und zu reagieren, bevor sie klinische Arbeitsabläufe beeinträchtigen.
CloudWatch ist nicht nur ein Überwachungstool, sondern eine operationale Kontrollschicht, die ermöglicht:
- Echtzeitsichtbarkeit des Systems über verteilte Gesundheitsanwendungen
- Proaktive Problemerkennung durch Schwellenwerte und Anomalieerkennung
- Automatisierte Antworten auf Systemereignisse (z. B., Skalierung, Neustarts, Benachrichtigungen)
In komplexen Gesundheitsumgebungen, in denen Systeme EHR-Plattformen, IoT-Geräte, APIs und Drittanbieter-Integrationen umfassen, ist dieses Maß an Sichtbarkeit entscheidend, um die Systemzuverlässigkeit und Datenintegrität zu gewährleisten. Infolgedessen wird CloudWatch zu einem Schlüsselbestandteil der Gesundheitsobservabilität in modernen cloudbasierten Systemen.
Wichtige Funktionen von CloudWatch für das Gesundheitswesen
CloudWatch bietet eine Reihe von Kernfunktionen, die die Gesundheitsobservabilität, schnelle Reaktion auf Vorfälle und operative Kontrolle in Gesundheitssystemen unterstützen.
Automatisierte Warnungen und Benachrichtigungen
Was es tut:
CloudWatch löst Warnungen aus, wenn vordefinierte Schwellenwerte oder Anomalie-Muster erkannt werden und informiert die Teams über integrierte Kommunikationskanäle.
Warum es im Gesundheitswesen wichtig ist:
Ermöglicht eine sofortige Reaktion auf kritische Probleme wie API-Ausfälle, hohe Latenzzeiten oder unbefugte Zugriffsversuche, bevor sie klinische Arbeitsabläufe oder die Patientenversorgung beeinträchtigen.
Beispiel:
Zum Beispiel kann eine Warnung ausgelöst werden, wenn die Fehlerquote einen definierten Schwellenwert überschreitet oder wenn unbefugte Zugriffsversuche festgestellt werden, wodurch die Teams reagieren können, bevor die Sicherheit oder Datenintegrität gefährdet wird.
Integration mit AWS Lambda
Was es tut:
CloudWatch integriert sich mit AWS Lambda, um automatisierte Aktionen als Reaktion auf Systemereignisse auszulösen, wie z.B. fehlgeschlagene Prozesse erneut auszuführen, Dienste neu zu starten oder die Infrastruktur zu skalieren.
Warum es im Gesundheitswesen wichtig ist:
Unterstützt automatisierte Reaktionen auf Vorfälle, wodurch Systeme sich selbst heilen können, ohne manuelle Eingriffe. Dies ist besonders wichtig in zeitkritischen Umgebungen, in denen Verzögerungen bei der Reaktion die Versorgung stören können.
Beispiel:
Zum Beispiel, wenn eine Datenverarbeitungsfunktion ausfällt, kann CloudWatch automatisch einen Wiederholungs- oder Neustartmechanismus auslösen, um sicherzustellen, dass kritische Patientendaten ohne manuelle Eingriffe verarbeitet werden.
KI-gestützte Anomalieerkennung
Was es tut:
CloudWatch verwendet maschinelles Lernen, um ungewöhnliche Muster im Systemverhalten zu erkennen, auch wenn keine festen Schwellenwerte definiert sind.
Warum es im Gesundheitswesen wichtig ist:
Hilft bei der Erkennung abnormalen Systemverhaltens, wie z.B. unerwarteten Spitzen bei der API-Nutzung oder Rückgängen von Daten von medizinischen Geräten, und ermöglicht eine proaktive Problemlösung, bevor sie die Patientenversorgung beeinflusst.
Beispiel:
Zum Beispiel kann ein plötzlicher Rückgang der eingehenden Daten von angeschlossenen medizinischen Geräten auf einen Geräteausfall oder Verbindungsprobleme hinweisen, sodass die Teams untersuchen können, bevor die Patientenüberwachung betroffen ist.
Wie AWS CloudWatch funktioniert
CloudWatch funktioniert als ein kontinuierlicher Überwachungszyklus, der Systemdaten in Echtzeit sammelt, verarbeitet und darauf reagiert. Dieser Prozess kann als Schleife dargestellt werden, die aus vier Hauptphasen besteht:
Sammlung
CloudWatch sammelt Metriken und Protokolle von AWS-Ressourcen, Anwendungen und verbundenen Systemen, einschließlich Servern, APIs, Datenbanken und IoT-Geräten.
Überwachung
Die gesammelten Daten werden durch Dashboards visualisiert, die es den Teams ermöglichen, das Systemverhalten zu verfolgen, Metriken und Protokolle zu korrelieren und Leistungsprobleme oder Anomalien zu identifizieren.
Handeln
Wenn vordefinierte Schwellenwerte überschritten oder ungewöhnliche Muster erkannt werden, löst CloudWatch Warnungen oder automatisierte Reaktionen aus, wie z.B. das Skalieren von Infrastruktur oder das Neustarten von Diensten.
Analysieren
CloudWatch ermöglicht eine tiefere Analyse des Systemverhaltens mithilfe historischer Daten, hochauflösender Metriken und Tools wie Metric Math, um Trends zu identifizieren und die Leistung zu optimieren.
Nach diesem Ablauf ermöglicht CloudWatch einen vollständig automatisierten Überwachungsprozess, bei dem Daten kontinuierlich gesammelt, analysiert und zur Auslösung von Aktionen verwendet werden.
In Gesundheitssystemen ist dieser Zyklus entscheidend, da er die automatische Erkennung von Anomalien ermöglicht, wie z.B. abnormaler API-Latenz oder Fehler in der Datenverarbeitung. Diese Probleme können sofort Warnungen auslösen und automatisierte Skalierungs- oder Wiederherstellungsmaßnahmen ohne manuelles Eingreifen auslösen, was sicherstellt, dass klinische Systeme reaktionsfähig und zuverlässig bleiben. Dieser Ansatz ist entscheidend für eine effektive Überwachung in Gesundheitssystemen und Echtzeit-Warnungen, bei denen eine sofortige Reaktion erforderlich ist.
Fallstudie: AWS CloudWatch in einem Gesundheitssystem
Untersuchen wir, wie AWS CloudWatch für Gesundheitsprojekte in einem unserer Gesundheitsprojekte implementiert wurde – einer Plattform zur Fernüberwachung von Patienten, die von Kliniken und Patienten genutzt wird.
Projektkontext
- Auf AWS-Infrastruktur aufgebaut
- Mehr als 500 AWS Lambda-Funktionen
- Zwei Plattformen: Web (für Praktiker) und mobil (für Patienten)
- Über 20.000 Nutzer auf den Plattformen
- 500+ Loggruppen und 1.400+ überwachte Metriken
Dies war ein System mit hoher Last in Echtzeit mit kontinuierlicher Datenverarbeitung, bei dem Patientendaten, Gerätesignale und Systemereignisse ohne Unterbrechung verarbeitet wurden.
Daten Sammlung und Visualisierung
Wir sammeln große Mengen an Protokollen, Metriken und Ereignissen aus mehreren AWS-Diensten, einschließlich:
- API Gateway — Anforderungsraten, Latenz, Fehlermeldungen
- AWS Lambda — Ausführungsdauer, Aufrufanzahl, Fehlerraten
- DynamoDB — Nutzung der Lese-/Schreibkapazität, Drosselereignisse
CloudWatch konsolidiert diese Daten in einem zentralen Dashboard und bietet Echtzeitsicht auf das Systemverhalten.
Dies ermöglicht es Teams, schnell zu identifizieren:
- Leistungsengpässe
- fehlerhafte Dienste
- abnormales Systemverhalten
und Probleme bis zu ihrer genauen Quelle zurückzuverfolgen.
Alarmkonfiguration, Metriken und Ereignisse
Wir haben Alarme basierend auf kritischen Systemschwellenwerten und Echtzeitevents konfiguriert.
Beispiele für Alarme sind:
- Latenzalarme, die ausgelöst werden, wenn die API-Antwortzeit definierte Schwellenwerte überschreitet (z. B. >300–500 ms)
- Fehlerratealarme, die aktiviert werden, wenn die Fehlerraten akzeptable Werte überschreiten (z. B. >2–5%)
- Alarme bei unbefugtem Zugriff, die bei verdächtigen Authentifizierungsversuchen oder ungewöhnlichen Zugriffsmustern ausgelöst werden
Diese Alarme können im Code definiert oder direkt in CloudWatch konfiguriert werden.
Metriken und Ereignisse werden auch verwendet, um das Systemverhalten zu automatisieren, wie zum Beispiel:
- Skalierung der Infrastruktur bei erhöhter Last
- Auslösen von Benachrichtigungen für Betriebsteams
- Einleiten von Wiederherstellungsmaßnahmen für fehlgeschlagene Prozesse
Auswirkungen
Mit diesem Setup erreichte das System:
- Schnellere Erkennung und Behebung von Leistungsproblemen
- Weniger Ausfallzeiten bei patientenorientierten Dienstleistungen
- Verbesserte Zuverlässigkeit der Echtzeitdatenverarbeitung
- Bessere Kontrolle über das Infrastrukturverhalten unter Last
Am wichtigsten ist, dass das Überwachungssystem sicherstellte, dass kritische Arbeitsabläufe im Gesundheitswesen stabil und reaktionsschnell blieben, auch unter hoher Last und kontinuierlichen Datenströmen.
Beispiele für die Verwendung von CloudWatch in unserem Gesundheitsprojekt
Schauen wir uns näher an, wie CloudWatch in dem Gesundheitsprojekt funktioniert, das wir zuvor vorgestellt haben.
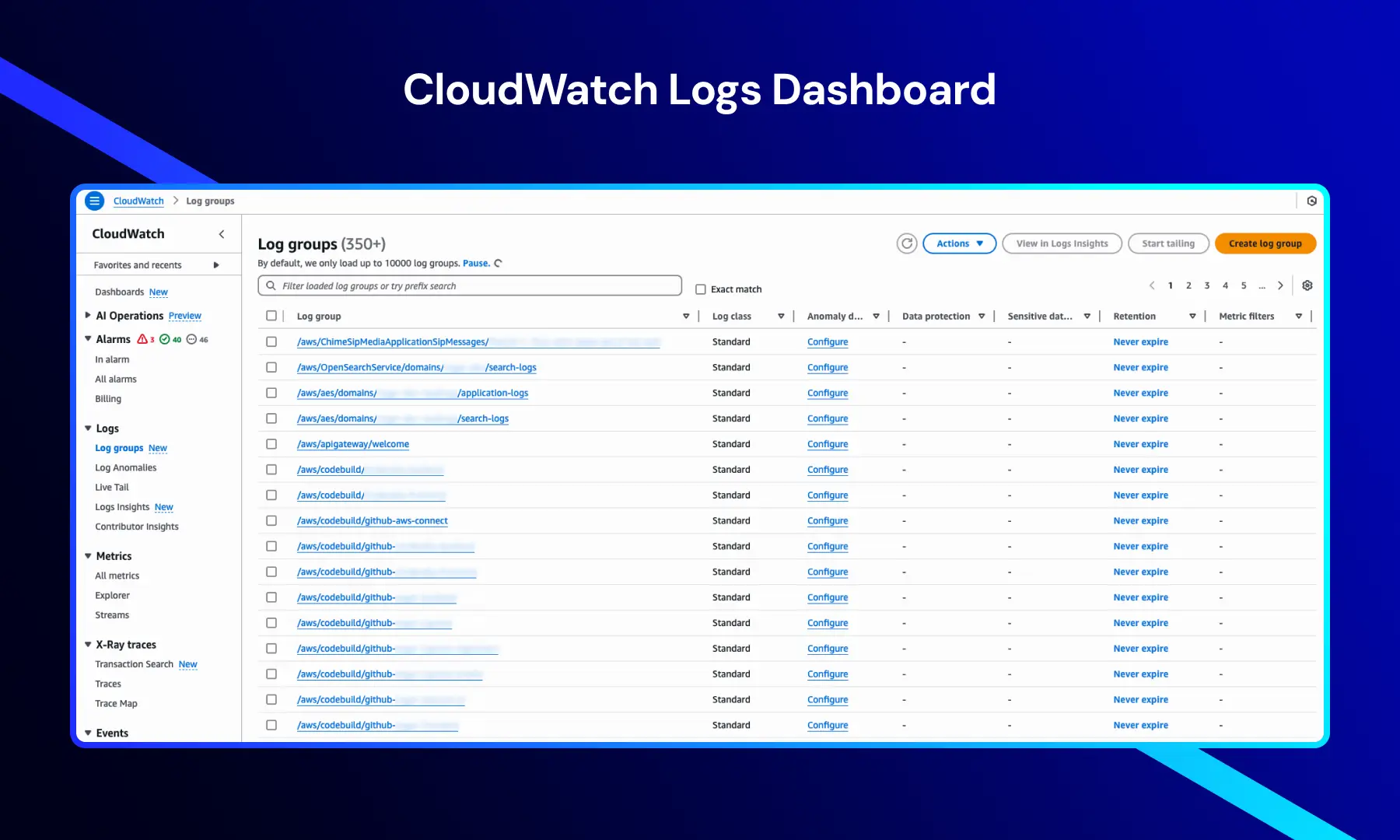
CloudWatch-Protokolldashboard
Diese Ansicht zeigt Protokollgruppen, die Protokolle aus verschiedenen AWS-Diensten und -Ressourcen organisieren und speichern.
Sie bietet wichtige Informationen wie:
- Protokollgruppennamen — Protokolle, die von Anwendungen, Infrastruktur und AWS-Diensten generiert werden
- Protokollklasse — typischerweise auf Standard für die Standardprotokollverarbeitung eingestellt
- Aufbewahrungseinstellungen — oft auf „Nie ablaufen“ für langfristige Analysen konfiguriert
- Anomalieerkennungs konfigurierung — ermöglicht die Identifizierung ungewöhnlicher Protokollmuster
Navigationsoptionen wie Alarme, Metriken, X-Ray-Transkripte und Ereignisse bieten Zugang zu den vollständigen Überwachungs- und Analysefähigkeiten von CloudWatch.
Diese Ansicht ist entscheidend für das zentrale Protokollmanagement und eine effiziente Fehlersuche in verteilten Systemen.
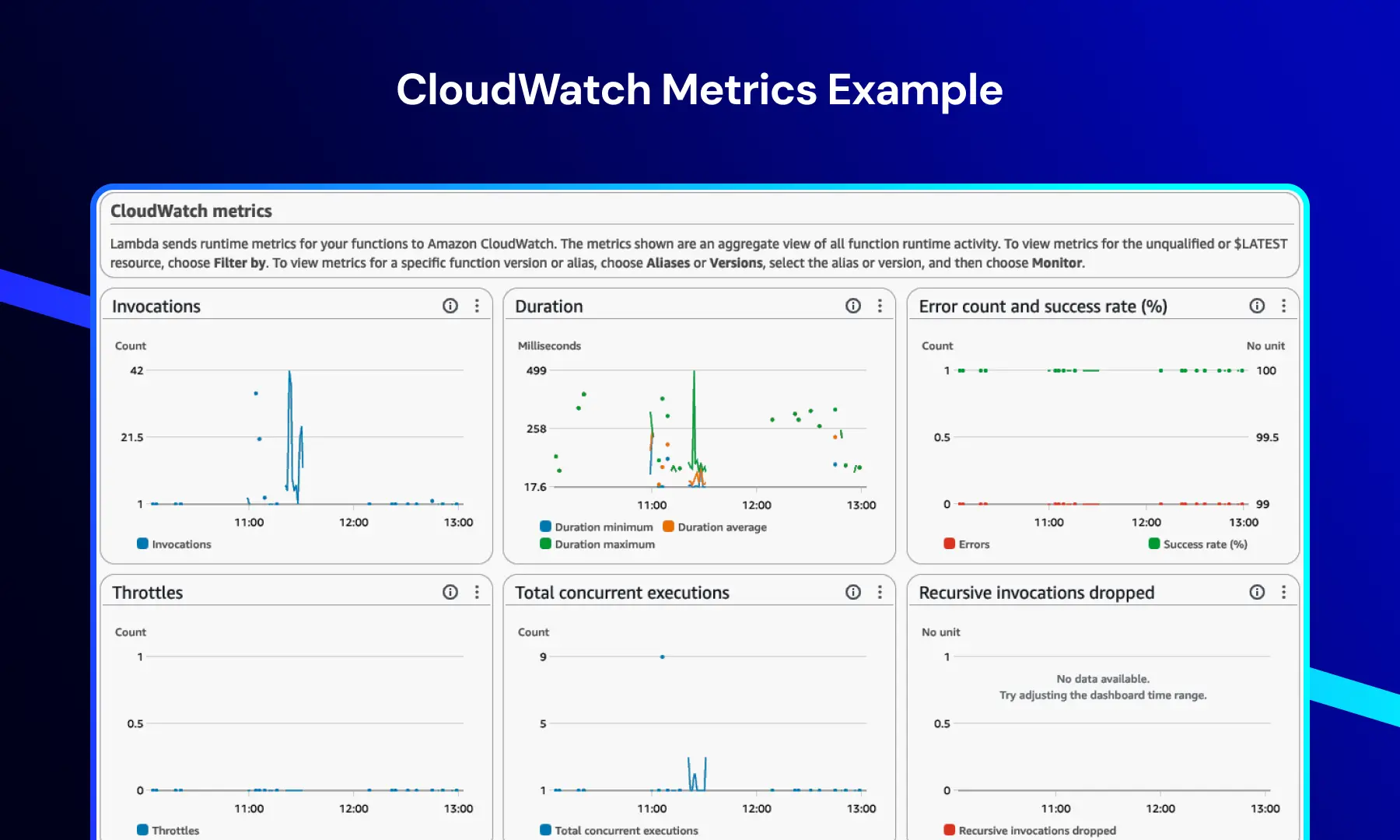
CloudWatch-Metriken
Dieses Dashboard bietet Echtzeiteinblicke in die System- und Anwendungsleistung.
Es umfasst typischerweise:
- Funktionsaufrufe
- Ausführungsdauer
- Fehlerraten
- Drosselungsevents
Dies ermöglicht es den Teams, Leistungstrends zu überwachen, Engpässe zu erkennen und die Systemstabilität unter Last aufrechtzuerhalten.
Lambda-Funktionsmetriken
Dieses Dashboard konzentriert sich auf detaillierte Leistungsmetriken für AWS Lambda-Funktionen.
Wichtige Erkenntnisse sind:
- Teuerste Aufrufe — Identifizierung von Funktionen mit dem höchsten Ressourcenverbrauch
- Ausführungsdauer vs. berechnete Dauer — Verständnis des Kostenverhaltens basierend auf den Abrechnungsrichtlinien von AWS
- Zugriff auf detaillierte Protokolle — ermöglicht schnelles Debugging und Leistungsoptimierung
Dieses Maß an Sichtbarkeit ist entscheidend für die Optimierung sowohl der Leistung als auch der Infrastrukturkosten in ereignisgesteuerten Gesundheitssystemen.

![Cloud Software Development [AWS].webp](/static/Cloud_Software_Development_AWS_a351611d38.webp)
Vorteile von AWS CloudWatch für das Gesundheitswesen
CloudWatch bietet Gesundheitssystemen die Sichtbarkeit und Kontrolle, die erforderlich sind, um Leistung, Zuverlässigkeit und Sicherheit in komplexen, Echtzeit-Umgebungen aufrechtzuerhalten.
Wichtige Vorteile sind:
Vollständige Beobachtbarkeit über Systeme hinweg
CloudWatch ermöglicht eine End-to-End-Beobachtbarkeit im Gesundheitswesen über APIs, Datenbanken, Infrastruktur und verbundene medizinische Geräte, sodass Teams das Systemverhalten in Echtzeit verstehen und schnell Anomalien erkennen können.
Schnellere Reaktion auf Vorfälle
Automatisierte Warnmeldungen und Echtzeitüberwachung reduzieren die Reaktionszeit und helfen den Teams, Probleme zu erkennen und zu lösen, bevor sie klinische Arbeitsabläufe oder die Patientenversorgung beeinträchtigen.
Reduzierte Ausfallzeiten
Frühe Erkennung von Anomalien und automatisierte Wiederherstellungsmaßnahmen minimieren Serviceunterbrechungen in kritischen Gesundheitssystemen.
Verbesserte betriebliche Effizienz
Klare Sichtbarkeit der Systemleistung ermöglicht es den Teams, den Ressourcenverbrauch zu optimieren und ein stabiles Systemverhalten unter unterschiedlichen Lastbedingungen aufrechtzuerhalten.
Verbesserte Compliance und Sicherheit
Kontinuierliches Monitoring und Protokollierung unterstützen die Prüf-Anforderungen und helfen, unbefugten Zugriff oder ungewöhnliche Systemaktivitäten zu erkennen.
Skalierbarkeit
CloudWatch wächst mit dem Systemwachstum und unterstützt steigende Datenvolumina, Benutzer und verbundene Geräte, ohne dass die Sichtbarkeit verloren geht.
Ist es möglich, CloudWatch nicht zu verwenden?
Ja, es gibt Alternativen zu CloudWatch, und in einigen Fällen können sie je nach Systemarchitektur und Teampräferenzen geeigneter sein.
Zu den gängigen Alternativen gehören:
- Datadog — bietet fortschrittliche Überwachungsfunktionen mit einer starken Benutzeroberfläche und umfangreichen Visualisierungstools
- Prometheus + Grafana — Open-Source-Lösung, die flexible Metriksammlung und Visualisierung bietet und häufig in benutzerdefinierten oder Multi-Cloud-Umgebungen verwendet wird
- Elastic Stack (ELK) — fokussiert auf zentrale Protokollverwaltung und Suchfunktionen
- New Relic — bietet vollständige Überwachung des Stacks mit starker Unterstützung für die Überwachung der Anwendungsleistung
Die Wahl hängt jedoch weitgehend davon ab, wie eng Ihr System mit AWS integriert ist.
Vergleichsübersicht
| Tool | Hauptvorteil | Komplikationen |
|---|---|---|
| Datadog | Bessere UI und Benutzererfahrung | Höhere Kosten bei Skalierung |
| Prometheus | Sehr flexibel und anpassbar | Komplexe Einrichtung und Wartung |
| CloudWatch | Beste Lösung für AWS-native Systeme | Begrenzte Flexibilität außerhalb von AWS |
CloudWatch bleibt eine praktische Wahl für auf AWS basierende Gesundheitssysteme aufgrund seiner nativen Integration, geringeren Betriebskosten und nahtlosen Skalierbarkeit.
Für Teams, die vollständig innerhalb von AWS arbeiten, verringert es den Bedarf an zusätzlichen Tools und vereinfacht die Überwachungsarchitektur, ohne die Sichtbarkeit oder Kontrolle zu beeinträchtigen.
Implementierungsschritte für AWS CloudWatch
Die Implementierung von CloudWatch in Gesundheitssystemen erfordert nicht nur eine ordnungsgemäße Einrichtung, sondern auch einen strukturierten Ansatz, um häufige Fallstricke zu vermeiden, die Leistung, Kosten und Zuverlässigkeit beeinträchtigen können.
1. Überwachung einrichten
Aktivieren Sie CloudWatch für alle relevanten AWS-Dienste und definieren Sie die wichtigsten Metriken, die die Systemgesundheit und -leistung widerspiegeln.
- Überwachen Sie APIs, Datenbanken, Rechenservices und Integrationen
- Installieren Sie CloudWatch-Agenten, wo erforderlich (z. B. für benutzerdefinierte Server)
- Konzentrieren Sie sich auf kritische Metriken wie Latenz, Fehlerraten und Systemlast
Best Practice:
Beginnen Sie mit einer minimalen, aber sinnvollen Menge an Metriken, die mit realen Systemrisiken verbunden sind (z. B. API-Latenz, fehlgeschlagene Anfragen, Datenverzögerungen).
Was nicht zu tun ist:
Vermeiden Sie es, von Anfang an zu viele Metriken zu verfolgen — dies erzeugt Rauschen, erhöht die Kosten und erschwert die Identifizierung echter Probleme.
2. Dashboards und Warnungen konfigurieren
Erstellen Sie Dashboards und Warnungen, die realen betrieblichen Prioritäten entsprechen, anstatt generischen Systemmetriken.
- Erstellen Sie Dashboards für Schlüssel-Workflows (z. B., Patientdatenfluss, API-Leistung)
- Alerts für Latenz, Fehlerraten und abnormales Systemverhalten festlegen
- Schwellenwerte basierend auf der tatsächlichen Systemnutzung definieren, nicht auf Annahmen
Beste Praxis:
Alerts mit geschäftskritischen Szenarien abstimmen, wie z.B. verzögerter Zugriff auf Patientenakten oder gescheiterte Datenübertragungen.
Was man vermeiden sollte:
Vermeiden Sie überempfindliche Alerts oder schlecht definierte Schwellenwerte — dies führt zu Alertmüdigkeit und ignorierten Benachrichtigungen.
3. Automatisieren Sie Antworten
Verwenden Sie CloudWatch-Integrationen, um Systemreaktionen auf Vorfälle zu automatisieren.
- Triggern Sie AWS Lambda-Funktionen für Wiederholungs-, Skalierungs- oder Wiederherstellungsaktionen
- Konfigurieren Sie Auto-Scaling basierend auf Last- und Leistungsmetriken
- Integrieren Sie Benachrichtigungen mit Incident-Management-Tools
Beste Praxis:
Automatisieren Sie Antworten für vorhersehbare Fehler (z.B. Wiederholungsversuche bei transienten Fehlern, Skalierung während Verkehrsspitzen).
Was man vermeiden sollte:
Verlassen Sie sich nicht vollständig auf manuelles Eingreifen — in Gesundheitssystemen kann eine verzögerte Reaktion die Systemzuverlässigkeit direkt beeinträchtigen.
4. Testen und kontinuierlich optimieren
Monitoring ist keine einmalige Einrichtung — es erfordert regelmäßige Tests und Optimierung.
- Überprüfen Sie, ob Alerts korrekt ausgelöst werden
- Simulieren Sie Fehlerszenarien (z.B. API-Ausfallzeiten, Datenverzögerungen)
- Überprüfen und passen Sie regelmäßig Schwellenwerte, Metriken und Alert-Logik an
Beste Praxis:
Optimieren Sie das Monitoring kontinuierlich basierend auf echten Vorfällen und Systemverhalten.
Was man vermeiden sollte:
Vermeiden Sie einen „Set and Forget“-Ansatz — veraltete Konfigurationen verpassen oft kritische Probleme oder erzeugen irrelevante Alerts.
Fazit
AWS CloudWatch ist eine praktische Wahl für das Monitoring von Gesundheitssystemen in AWS-Umgebungen und bietet die Sichtbarkeit, Alarmierung und Kostenkontrolle, die für Produktionsumgebungen erforderlich sind.
In komplexen Gesundheitsarchitekturen, in denen mehrere Dienste, Integrationen und Echtzeitdatenströme zuverlässig operieren müssen, ermöglicht CloudWatch den Teams, Stabilität zu erhalten, Probleme frühzeitig zu erkennen und ohne Verzögerung zu reagieren.
Bei richtiger Implementierung unterstützt es vollständige Sichtbarkeit, schnellere Reaktionen auf Vorfälle und ein vorhersehbareres Systemverhalten unter Last.
Da Gesundheitssysteme weiterhin skalieren und datengestützt werden, ist eine gut definierte Überwachungs- und Alarmierungsstrategie nicht mehr optional — sie ist ein zentraler Bestandteil des Aufbaus zuverlässiger und wartbarer Software.
Wenn Sie eine Gesundheitsplattform auf AWS entwerfen oder skalieren, kann eine gut konfigurierte CloudWatch-Einrichtung betriebliche Risiken erheblich reduzieren und die Systemleistung verbessern.
Benötigen Sie Hilfe bei der Implementierung von CloudWatch in Ihrem Gesundheitsprojekt?
Bei JetBase helfen wir Gesundheitsteams, Überwachungssysteme zu entwerfen, die über die grundlegende Einrichtung hinausgehen — mit Fokus auf Zuverlässigkeit, Kosteneffizienz und reale Leistung.
Ob Sie nun eine neue Plattform erstellen oder eine bestehende optimieren, wir können Ihnen helfen, eine Überwachungsstrategie einzurichten, die zu Ihrer Architektur und Ihren Geschäftszielen passt.
Kontaktieren Sie uns, um Ihr Projekt zu besprechen oder eine Beratung zu erhalten.