I den här artikeln kommer vi att utforska AWS CloudWatch — ett mångsidigt övervaknings- och hanteringsverktyg som vi rekommenderar för utvecklingsprojekt inom hälso- och sjukvård. CloudWatch erbjuder realtidsinsyn i infrastruktur och applikationer, vilket möjliggör snabba åtgärder för att bibehålla prestanda och tillförlitlighet.
Detta är särskilt viktigt inom vårdsystem, som hanterar känsliga patientdata, erbjuder kontinuerlig övervakning och kör kritiska applikationer där även små störningar kan påverka kliniska arbetsflöden och tillgången till data. Övervakning i hälso- och sjukvårdssystem är avgörande eftersom dessa miljöer fungerar i realtid, vilket lämnar inget utrymme för förseningar i upptäckten eller svaret. Detta gör övervakning och varning av hälso- och sjukvårdssystem till en kritisk komponent i pålitlig systemarkitektur.
Vikten av övervakning och varningar inom hälso- och sjukvård
Hälso- och sjukvårdssystem verkar i realtidsmiljöer där även små störningar kan påverka kliniska arbetsflöden och operationell effektivitet.
I praktiken ser misslyckanden sällan ut som en fullständig systemavbrott. Istället uppstår de som små men kritiska problem:
- API-avbrott resulterar i ingen åtkomst till elektroniska patientjournaler (EHR), vilket försenar diagnos- och behandlingsbeslut
- Försenade varningar innebär att onormala patientvitaler, såsom hjärtfrekvens eller syrenivåer, inte eskaleras i tid
- Misslyckade integrationer hindrar laboratorieresultat eller bilddata från att nå vårdteamet
Även när systemen förblir tekniskt operativa, kan dessa problem tyst störa vården. Övervaknings- och varningssystem är avgörande eftersom de upptäcker dessa misslyckanden tidigt och möjliggör snabb respons. Utan korrekt insyn upptäcker team ofta problem först efter att de börjar påverka användare eller patienter.
Även en kort fördröjning i varningsleveransen (till exempel 30–60 sekunder) kan påverka tidskänsliga arbetsflöden såsom övervakning av intensivvård eller akutsystem, där reaktionstid är avgörande.
Robust övervakning säkerställer:
- Kontinuerlig åtkomst till kritiska system såsom EHR, fjärrövervakning av patienter och plattformar för telemedicin
- Tidig upptäckte av avvikelser innan de eskalerar till större misslyckanden
- Pålitlig dataflöde mellan system, särskilt i integrationsintensiva miljöer
Inom hälso- och sjukvård handlar övervakning inte bara om infrastrukturens stabilitet. Det handlar om att bevara integriteten i kliniska arbetsflöden, där tid, noggrannhet och tillgång till data direkt påverkar resultat.
Förbättra patientsäkerheten med AWS CloudWatch
Övervakning och varning av hälso- och sjukvårdssystem spelar en kritisk roll för att upprätthålla patientsäkerhet genom att säkerställa att data är tillgänglig, korrekt och levererad i tid. I praktiken kräver detta att man spårar specifika systembeteenden och reagerar omedelbart på misslyckanden.
Elektroniska Patientjournaler (EHR)
För EHR-system beror kontinuerlig åtkomst till patientdata på stabiliteten i backend-tjänster och databaser.
- Vad övervakas: API-latens, databasens svarstid, felprocent
- Typ av varning: Tröskelbaserade varningar vid latensökningar och ökningar av felprocent
- Exempel på utlösare: API-svarstiden överskrider definierade gränser, databasfrågor saktas ner eller felprocenten ökar över normala nivåer
Övervakning av dessa mätvärden säkerställer oavbruten tillgång till patientjournaler och förhindrar förseningar i kliniska beslut.
Kliniska beslutstödsystem (CDSS)
CDSS-plattformar förlitar sig på snabb bearbetning av kliniska regler och sömlös datautbyte med externa system.
- Vad övervakas: Regelbearbetningstid, integrationsstatus med laboratoriehallar, systemexekveringsförseningar
- Typ av varning: Händelsebaserade och latensvarningar för försenad eller misslyckad bearbetning
- Exempel på utlösare: Försenad exekvering av kliniska regler, misslyckade API-anrop till laboratoriehallar eller saknad indata
Varningar kan utlösas när kliniska regler inte bearbetas i tid eller när integrationer misslyckas, vilket minskar risken för missade rekommendationer eller felaktiga behandlingsbeslut.
Fjärrövervakning av patienter (RPM)
RPM-system är beroende av kontinuerligt dataflöde från medicinska enheter och realtidsanalys av patientens vitala tecken.
- Vad övervakas: Enhetsanslutning, datainmatningshastighet, onormala vitala trösklar
- Typ av varning: Realtidsvarningar för saknad data eller onormala patientmått
- Exempel på utlösare: Enheten kopplar ifrån, minskning av datatransmissionsfrekvens eller vitala tecken överstiger fördefinierade trösklar
Dessa varningar säkerställer att vårdteam omedelbart informeras om både tekniska problem och potentiella patientrisker, vilket möjliggör snabbare åtgärder.
Kostnadsoptimering och effektivitet med AWS CloudWatch
Molnkostnader kan växa snabbt i vårdmiljöer om de lämnas oövervakade. I AWS CloudWatch-vårdmiljöer beror kostnadsoptimering på insyn i specifika kostnadsdrivare snarare än allmän systemprestanda.
I praktiken innebär detta att identifiera var kostnader genereras och optimera systembeteende baserat på verkliga användningsmönster.
De vanligaste kostnadsdrivarna i AWS-baserade sjukvårdssystem inkluderar:
- Lambda-exekveringstid — längre exekveringstider ökar direkt beräkningskostnader
- Anropstäthet — högfrekventa utlösningar (särskilt i händelsedrivna system) kan betydligt öka den totala användningen
- Loggvolym — överdriven eller ostrukturerad loggning leder till höga lagrings- och inmatningskostnader
- Metriklagring — stora mängder anpassade metrik, särskilt med hög granularitet, kan öka övervakningskostnaderna
CloudWatch ger detaljerad insyn i dessa områden, vilket gör att team kan spåra användningsmönster och göra riktade optimeringar.
I stället för att brett analysera systembeteende kan team identifiera exakt var kostnader genereras och vidta åtgärder, som att minska Lambda-exekveringstid, begränsa onödiga anrop eller optimera loggningsstrategier.
Exempel från praktiken
Till exempel, vi upptäckte att vissa AWS Lambda-funktioner i ett av våra sjukvårdsprojekt konsumerade upp till $300 per månad. Genom att analysera CloudWatch-metrik optimerade vi funktionerna och sänkte kostnaderna till endast $20–30—vilket resulterade i besparingar på nästan $1,000.
De största kostnadsdrivarna vi vanligtvis ser är ineffektiv Lambda-exekveringstid, överdriven loggning och ooptimerade återföringsmekanismer.
Vad är AWS CloudWatch?
Amazon CloudWatch är en övervaknings- och observationsservice som är utformad för att ge realtidsinsyn i applikationer, infrastruktur och systembeteende.
Inom sjukvårdssystem, där flera tjänster, integrationer och dataflöden verkar samtidigt, fungerar CloudWatch som ett centralt lager som samlar in och korrelerar operativ data över hela systemet.
CloudWatch fungerar över tre huvudlager — metrik, loggar och händelser — som tillsammans möjliggör fullständig observationsförmåga av distribuerade system.
Det sammanställer tre kärntyper av data:
- Metrik — prestationsindikatorer som latens, CPU-användning, felprocent och begärningsvolym
- Loggar — detaljerade poster av systemhändelser, applikationsbeteende och fel
- Ändringar — systemförändringar, utlösningar och automatiserade svar
Denna enhetliga vy gör det möjligt för team att upptäcka problem snabbare, förstå deras rotorsak och svara innan de påverkar kliniska arbetsflöden.
CloudWatch är inte bara ett övervakningsverktyg utan ett operativt kontrollager som möjliggör:
- Realtidsinsyn i distribuerade sjukvårdsapplikationer
- Proaktiv upptäckte av problem genom trösklar och anomalidetektion
- Automatiserade svar på systemhändelser (t.ex., skalning, omstarter, aviseringar)
I komplexa vårdmiljöer, där system inkluderar EHR-plattformar, IoT-enheter, API:er och tredjepartsintegrationer, är denna nivå av synlighet avgörande för att upprätthålla systemets pålitlighet och dataintegritet. Som ett resultat blir CloudWatch en nyckelkomponent för vårdövervakning i moderna molnbaserade system.
Nyckelfunktioner i CloudWatch för vården
CloudWatch tillhandahåller en uppsättning kärnfunktioner som stödjer vårdövervakning, snabb händelsesvar och operativ kontroll i vårdsystem.
Automatiska aviseringar och meddelanden
Vad det gör:
CloudWatch utlöser aviseringar när fördefinierade trösklar eller anomalimönster upptäcks, och meddelar team via integrerade kommunikationskanaler.
Varför det är viktigt inom vården:
Gör att omedelbara åtgärder kan vidtas vid kritiska problem som API-fel, hög latens eller obehöriga åtkomstförsök innan de påverkar kliniska arbetsflöden eller patientvård.
Exempel:
Till exempel kan en avisering utlösas när felprocenten överskrider en definierad tröskel eller när obehöriga åtkomstförsök upptäckts, vilket gör att team kan agera innan säkerheten eller dataintegriteten äventyras.
Integration med AWS Lambda
Vad det gör:
CloudWatch integreras med AWS Lambda för att utlösa automatiserade åtgärder som svar på systemhändelser, som att försöka om processer som misslyckats, starta om tjänster eller skala infrastrukturen.
Varför det är viktigt inom vården:
Stöder automatiserat händelsesvar, vilket gör att system kan självläka utan manuell intervention. Detta är särskilt viktigt i tidkänsliga miljöer där förseningar i respons kan störa vårdleveransen.
Exempel:
Till exempel, om en databehandlingsfunktion misslyckas, kan CloudWatch automatiskt utlösa en omförsöknings- eller omstarts mekanism, vilket säkerställer att kritisk patientdata bearbetas utan manuell intervention.
AI-driven anomalidetektering
Vad det gör:
CloudWatch använder maskininlärningsmodeller för att upptäcka ovanliga mönster i systembeteende, även när inga fasta trösklar har definierats.
Varför det är viktigt inom vården:
Hjälper till att upptäcka onormalt systembeteende, som oväntade toppar i API-användning eller nedgångar i data från medicinska enheter, vilket möjliggör proaktiv problemlösning innan det påverkar patientvård.
Exempel:
Till exempel kan en plötslig nedgång i inkommande data från anslutna medicinska enheter signalera en enhetsfel eller anslutningsproblem, vilket gör att team kan undersöka innan patientövervakningen påverkas.
Hur AWS CloudWatch fungerar
CloudWatch fungerar som en kontinuerlig övervakningscykel som samlar in, bearbetar och agerar på systemdata i realtid. Denna process kan representeras som en slinga bestående av fyra nyckelfaser:
Inhämta
CloudWatch samlar in mätningar och loggar från AWS-resurser, applikationer och anslutna system, inklusive servrar, API:er, databaser och IoT-enheter.
Övervaka
De insamlade uppgifterna visualiseras genom instrumentpaneler, vilket gör det möjligt för team att spåra systembeteende, korrelera mätningar och loggar samt identifiera prestandaproblem eller avvikelser.
Agera
När fördefinierade trösklar överskrids eller ovanliga mönster upptäcks, utlöser CloudWatch larm eller automatiserade svar, såsom att skala infrastruktur eller starta om tjänster.
Analysera
CloudWatch möjliggör djupare analys av systembeteende med hjälp av historiska data, högupplösta mätningar och verktyg som Metric Math för att identifiera trender och optimera prestanda.
Enligt denna flöde möjliggör CloudWatch en helt automatiserad övervakningsprocess där data kontinuerligt samlas in, analyseras och används för att utlösa åtgärder.
I sjukvårdssystem är denna cykel avgörande eftersom den möjliggör automatisk upptäckte av avvikelser, såsom onormal API-latens eller fel i databehandling. Dessa problem kan omedelbart utlösa larm och automatiserade skalnings- eller återställningsåtgärder utan manuell intervention, vilket säkerställer att kliniska system förblir responsiva och tillförlitliga. Detta tillvägagångssätt är väsentligt för effektiv övervakning i sjukvårdssystem och realtidslarm, där omedelbara svar krävs.
Fallstudie: AWS CloudWatch i en Sjukvårdsmiljö
Låt oss undersöka hur AWS CloudWatch för sjukvårdsprojekt implementerades i ett av våra sjukvårdsprojekt — en plattform för fjärrövervakning av patienter som används av kliniker och patienter.
Projektkontext
- Byggd på AWS-infrastruktur
- Mer än 500 AWS Lambda-funktioner
- Två plattformar: webb (för vårdgivare) och mobil (för patienter)
- 20 000+ användare över plattformarna
- 500+ loggrupper och 1 400+ mätningar som övervakas
Datainsamling och Visualisering
Vi samlar in stora volymer av loggar, mätningar och händelser från flera AWS-tjänster, inklusive:
- API Gateway — begärningsfrekvenser, latens, felrespons
- AWS Lambda — exekveringstid, anropsantal, felprocent
- DynamoDB — läs-/skrivkapacitetsanvändning, begränsningshändelser
CloudWatch konsoliderar dessa data i ett centraliserat instrumentbräda som ger realtidsöversikt över systembeteendet.
Detta gör det möjligt för team att snabbt identifiera:
- prestandaflaskhalsar
- misslyckande tjänster
- onormalt systembeteende
och spåra problem tillbaka till deras exakta källa.
Alertkonfiguration, Metrik och Händelser
Vi konfigurerade varningar baserat på kritiska systemtrösklar och realtids händelser.
Exempel på varningar inkluderar:
- Latensvarningar utlöses när API:ts svarstid överstiger definierade trösklar (t.ex. >300–500 ms)
- Felratvarningar aktiveras när felrater överstiger acceptabla nivåer (t.ex. >2–5%)
- Obehörig åtkomstvarningar utlöses vid misstänkt autentisering eller ovanliga åtkomstmönster
Dessa varningar kan definieras i kod eller konfigureras direkt i CloudWatch.
Metrik och händelser används också för att automatisera systembeteende, såsom:
- skala infrastruktur under ökad belastning
- utlösa meddelanden för operativa team
- initiera återhämtningsåtgärder för misslyckade processer
Påverkan
Med denna uppsättning uppnådde systemet:
- Snabbare upptäckte och lösningar på prestationsproblem
- Minskad driftstid för patientvändande tjänster
- Förbättrad tillförlitlighet för realtidsdatabehandling
- Bättre kontroll över infrastrukturens beteende under belastning
Viktigast av allt säkerställde övervakningssystemet att kritiska hälsoarbetsflöden förblev stabila och responsiva, även under hög belastning och kontinuerliga datastreamar.
Exempel på CloudWatch-användning i vårt hälso- och sjukvårdsprojekt
Låt oss ta en närmare titt på hur CloudWatch fungerar inom det hälso- och sjukvårdsprojekt vi nämnde tidigare.
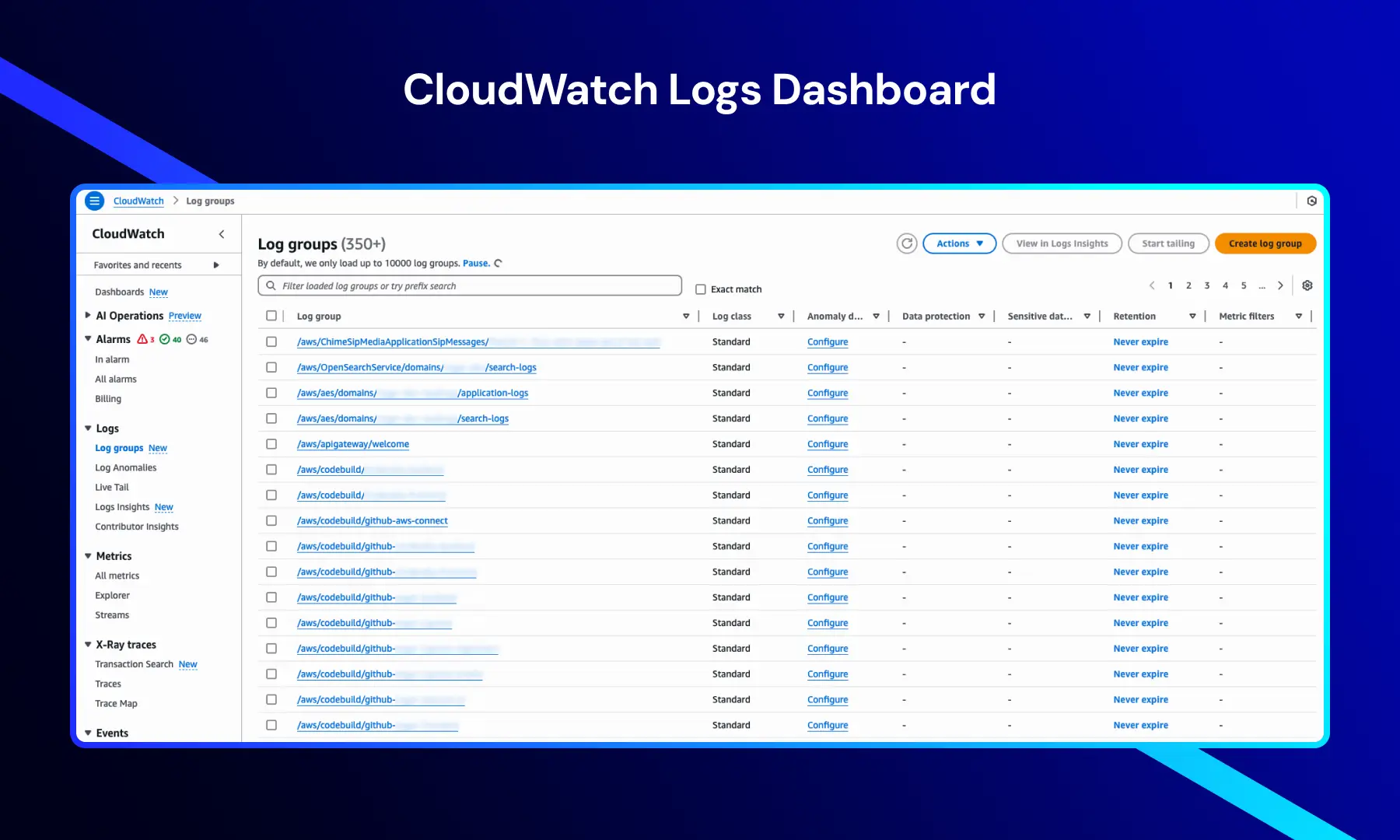
CloudWatch Loggar Dashboard
Denna vy visar loggrupper som organiserar och lagrar loggar från olika AWS-tjänster och resurser.
Den ger nyckelinformation såsom:
- Loggruppens namn — loggar genererade av applikationer, infrastruktur och AWS-tjänster
- Loggklass — inställd på Standard för standard logghantering
- Behållningsinställningar — oftast konfigurerad till "Aldrig utgå" för långsiktig analys
- Anomalidetekteringskonfiguration — möjliggör identifiering av ovanliga loggmönster
Navigeringsalternativ som Larm, Metrik, X-Ray-spår och Händelser ger tillgång till den fulla övervaknings- och analyskapaciteten hos CloudWatch.
Denna vy är väsentlig för centraliserat loggmanagement och effektiv felsökning över distribuerade system.
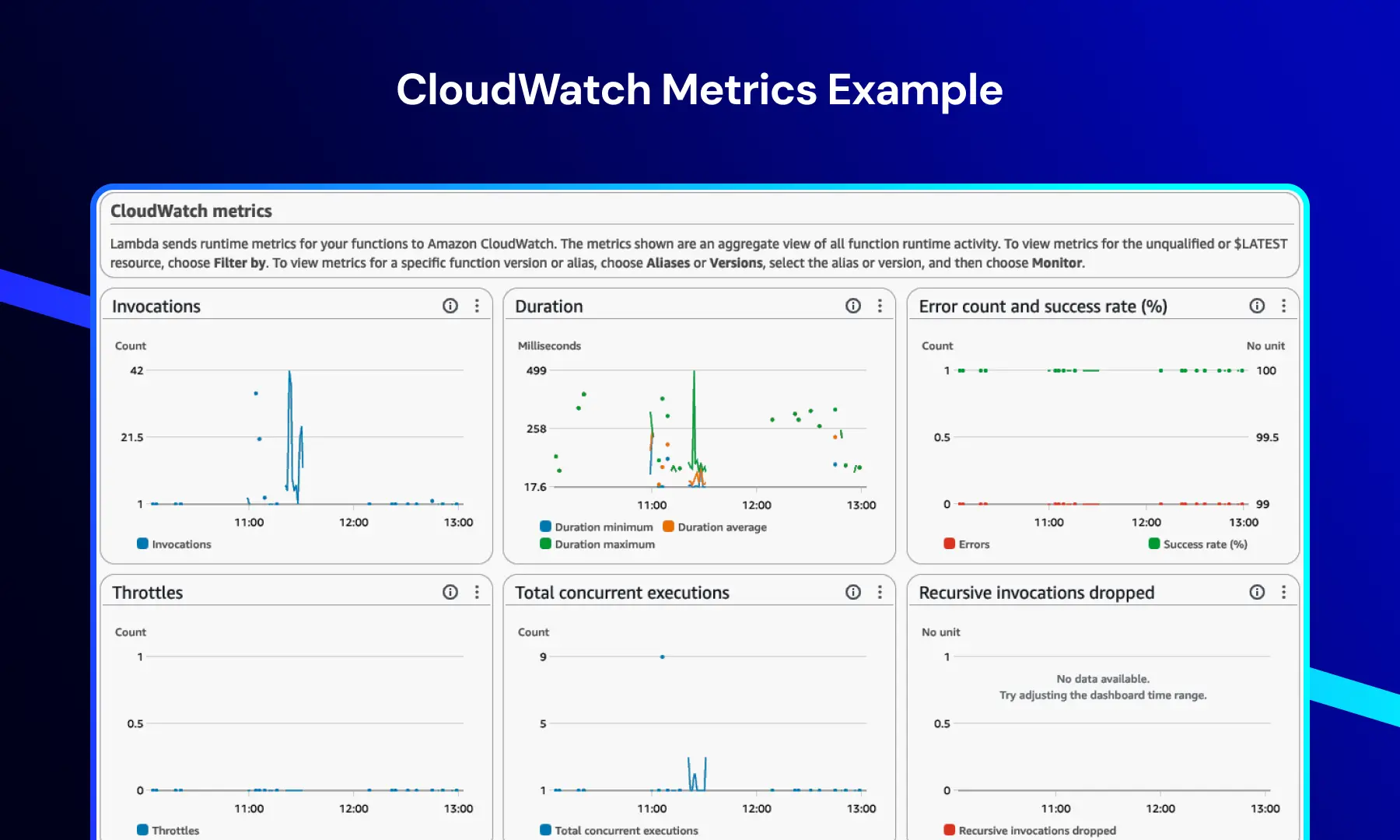
CloudWatch Metrik
Denna dashboard ger realtidsinsikter i system- och applikationsprestanda.
Det inkluderar vanligtvis:
- Funktionsanrop
- Körtid
- Felsiffror
- Begränsningshändelser
Detta gör det möjligt för team att övervaka prestandatrender, upptäcka flaskhalsar och upprätthålla systemstabilitet under belastning.
Lambda Funktionsmetrik
Denna instrumentpanel fokuserar på detaljerad prestandametrik för AWS Lambda-funktioner.
Nyckelinsikter inkluderar:
- De dyraste anropen — identifiera funktioner med högst resursförbrukning
- Körtid vs debiterad tid — förstå kostnadsbeteende baserat på AWS debiteringsregler
- Åtkomst till detaljerade loggar — möjliggör snabb felsökning och prestandaoptimering
Denna nivå av insyn är avgörande för att optimera både prestanda och infrastrukturkostnader i händelsedrivna hälsovårdssystem.

![Cloud Software Development [AWS].webp](/static/Cloud_Software_Development_AWS_a351611d38.webp)
Fördelar med AWS CloudWatch för Hälsovård
CloudWatch ger hälsovårdssystem den insyn och kontroll som krävs för att upprätthålla prestanda, tillförlitlighet och säkerhet i komplexa, realtidsmiljöer.
Nyckelfördelar inkluderar:
Fullständig observabilitet över system
CloudWatch möjliggör end-to-end hälsovårdsobservabilitet över API:er, databaser, infrastruktur och anslutna medicinska enheter, vilket gör att team kan förstå systembeteende i realtid och snabbt identifiera anomalier.
Snabbare incidentrespons
Automatiska varningar och övervakning i realtid minskar svarstiden, vilket hjälper team att upptäcka och åtgärda problem innan de påverkar kliniska arbetsflöden eller patientvård.
Minskad stilleståndstid
Tidig upptäckte av anomalier och automatiserade återställningsåtgärder minimerar avbrott i kritiska hälsovårdssystem.
Förbättrad operationell effektivitet
Tydlig insyn i systemprestanda gör att team kan optimera resursanvändning och upprätthålla stabilt systembeteende under varierande belastningsförhållanden.
Förbättrad regelefterlevnad och säkerhet
Kontinuerlig övervakning och loggning stödjer revisionskrav och hjälper till att upptäcka obehörig åtkomst eller ovanlig systemaktivitet.
Skalbarhet
CloudWatch växer med systemtillväxt, vilket stödjer ökande datavolymer, användare och anslutna enheter utan förlust av insyn.
Är det möjligt att inte använda CloudWatch?
Ja, alternativ till CloudWatch finns, och i vissa fall kan de vara mer lämpliga beroende på systemarkitektur och teampreferenser.
Vanliga alternativ inkluderar:
- Datadog — erbjuder avancerade övervakningsmöjligheter med ett starkt användargränssnitt och rika visualiseringsverktyg
- Prometheus + Grafana — öppen källkodslösning som erbjuder flexibel insamling och visualisering av mätvärden, ofta använda i anpassade eller multicloud-miljöer
- Elastic Stack (ELK) — fokuserad på centraliserad logghantering och sökmöjligheter
- New Relic — ger fullständig översyn över hela stacken med starkt stöd för övervakning av applikationsprestanda
Valet beror dock till stor del på hur tätt ert system är integrerat med AWS.
Översikt av Jämförelse
| Verktyg | Huvudfördel | Avvägningar |
|---|---|---|
| Datadog | Bättre UI och användarupplevelse | Högre kostnader i skala |
| Prometheus | Mycket flexibel och anpassningsbar | Komplex installation och underhåll |
| CloudWatch | Bästa alternativ för AWS-nativa system | Begränsad flexibilitet utanför AWS |
CloudWatch förblir ett praktiskt val för AWS-baserade hälso- och sjukvårdssystem på grund av dess inbyggda integration, lägre driftkostnader och sömlös skalbarhet.
För team som arbetar helt inom AWS minskar det behovet av ytterligare verktyg och förenklar övervakningsarkitekturen utan att kompromissa med synlighet eller kontroll.
Implementeringssteg för AWS CloudWatch
Att implementera CloudWatch i hälso- och sjukvårdssystem kräver inte bara korrekt konfiguration utan också en strukturerad metod för att undvika vanliga fällor som kan påverka prestanda, kostnader och tillförlitlighet.
1. Sätt upp övervakning
Aktivera CloudWatch för alla relevanta AWS-tjänster och definiera de viktiga mätvärdena som återspeglar systemhälsa och prestanda.
- Konfigurera övervakning för API:er, databaser, datortjänster och integrationer
- Installera CloudWatch-agenter där det behövs (t.ex. för anpassade servrar)
- Fokusera på kritiska mätvärden som latens, felkvoter och systembelastning
Bästa praxis:
Börja med en minimal men meningsfull uppsättning mätvärden knutna till verkliga systemrisker (t.ex. API-latens, misslyckade förfrågningar, datadelays).
Vad man inte ska göra:
Undvik att spåra för många mätvärden från början — detta skapar brus, ökar kostnaderna och gör det svårare att identifiera verkliga problem.
2. Konfigurera instrumentpaneler och aviseringar
Skapa instrumentpaneler och aviseringar som speglar verkliga operativa prioriteringar snarare än generiska system-mätvärden.
- Bygg instrumentpaneler för nyckelarbetsflöden (t.ex.
- Patientdataflöde, API-prestanda)
- Ställ in varningar för latens, felkvoter och onormalt systembeteende
- Definiera trösklar baserat på verklig systemanvändning, inte antaganden
Bästa praxis:
Justera varningar med affärskritiska scenarier, som försenad tillgång till patientjournaler eller misslyckad dataleverans.
Vad man inte ska göra:
Undvik överdrivet känsliga varningar eller dåligt definierade trösklar — detta leder till varningströtthet och ignorerade meddelanden.
3. Automatisera svar
Använd CloudWatch-integrationer för att automatisera systemreaktioner på incidenter.
- Utlösa AWS Lambda-funktioner för försök, skalning eller återställningsåtgärder
- Konfigurera automatisk skalning baserat på belastning och prestandamått
- Integrera meddelanden med incidenthanteringsverktyg
Bästa praxis:
Automatisera svar på förutsägbara fel (t.ex. försök för tillfälliga fel, skalning under trafiktoppar).
Vad man inte ska göra:
Förlita dig inte helt på manuell intervention — inom hälso- och sjukvårdssystem kan fördröjda svar direkt påverka systemets tillförlitlighet.
4. Testa och optimera kontinuerligt
Övervakning är ingen engångsupplägg — det kräver regelbundet testande och optimering.
- Validera att varningar utlöses korrekt
- Simulera felscenarier (t.ex. API-nedtid, databolag)
- Granska och justera trösklar, mått och varningslogik regelbundet
Bästa praxis:
Kontinuerligt förfina övervakningen baserat på verkliga incidenter och systembeteende.
Vad man inte ska göra:
Undvik en "stäng och glöm"-metod — föråldrade konfigurationer missar ofta kritiska problem eller genererar irrelevanta varningar.
Sammanfattning
AWS CloudWatch är ett praktiskt val för övervakning av hälso- och sjukvårdssystem i AWS-miljöer, som ger den insyn, varning och kostnadskontroll som behövs för produktionsmiljöer.
I komplexa hälsoarkitekturer, där flera tjänster, integrationer och realtidsdataflöden måste fungera pålitligt, gör CloudWatch det möjligt för team att upprätthålla stabilitet, upptäcka problem tidigt och svara utan fördröjning.
När det implementeras korrekt stöder det full insyn, snabbare incidentrespons och mer förutsägbart systembeteende under belastning.
Allteftersom hälso- och sjukvårdssystem fortsätter att växa och bli mer datadrivna är det inte längre valfritt att ha en väl definierad övervaknings- och varningsstrategi — det är en kärnkomponent i att bygga pålitlig och underhållbar programvara.
Om du utformar eller skalar en hälso- och sjukvård plattform på AWS kan en välkonfigurerad CloudWatch-uppsättning avsevärt minska driftsrisker och förbättra systemprestanda.
Behöver du hjälp med att implementera CloudWatch i ditt hälso- och sjukvårdsprojekt?
På JetBase hjälper vi hälso- och sjukvårdsteam att utforma övervakningssystem som går bortom grundläggande uppsättning — med fokus på tillförlitlighet, kostnadseffektivitet och verklig prestanda.
Oavsett om du bygger en ny plattform eller optimerar en befintlig, kan vi hjälpa dig att skapa en övervakningsstrategi som passar din arkitektur och dina affärsmål.
Kontakta oss för att diskutera ditt projekt eller få en konsultation.