I denne artikel vil vi udforske AWS CloudWatch—et alsidigt overvågnings- og administrationsværktøj, som vi anbefaler til udviklingsprojekter inden for sundhedspleje. CloudWatch tilbyder realtidsindsigt i infrastruktur og applikationer, hvilket muliggør rettidige handlinger for at opretholde ydeevne og pålidelighed.
Dette er især vigtigt i sundhedssystemer, som håndterer følsomme patientdata, giver kontinuerlig overvågning og kører kritiske applikationer, hvor selv små forstyrrelser kan påvirke kliniske arbejdsgange og datatilgængelighed. Overvågning i sundhedssystemer er essentiel, fordi disse miljøer fungerer i realtid, hvilket efterlader ingen mulighed for forsinkelser i opdagelse eller respons. Dette gør overvågning og alarmering i sundhedssystemer til en kritisk komponent i en pålidelig systemarkitektur.
Vigtigheden af Overvågning og Alarmer i Sundhedsvæsenet
Sundhedssystemer opererer i realtidsmiljøer, hvor selv små forstyrrelser kan have direkte indflydelse på kliniske arbejdsgange og operationel effektivitet.
I praksis ligner fejl sjældent en komplet systemnedbrud. I stedet viser de sig som små, men kritiske problemer:
- API-nedetid resulterer i ingen adgang til Elektroniske Sundhedsoptegnelser (EHR), hvilket forsinker diagnose- og behandlingsbeslutninger
- Forsinkede alarmer betyder, at unormale patientvitaler, såsom hjertefrekvens eller iltniveauer, ikke eskaleres i tide
- Mislykkede integrationer forhindrer laboratorieresultater eller billeddata i at nå pleje-teamet
Selv når systemer forbliver teknisk operationelle, kan disse problemer stille forstyrre plejelevering. Overvågnings- og alarmeringssystemer er essentielle, fordi de tidligt opdager disse fejl og muliggør hurtig respons. Uden ordentlig synlighed opdager teams ofte problemer først, efter de begynder at påvirke brugere eller patienter.
Selv en kort forsinkelse i alarmlevering (for eksempel 30–60 sekunder) kan påvirke tidsfølsomme arbejdsgange såsom ICU-overvågning eller nødsystemer, hvor reaktionstid er kritisk.
Robust overvågning sikrer:
- Kontinuerlig adgang til kritiske systemer såsom EHR, fjernovervågning af patienter og telemedicinske platforme
- Tidlig opdagelse af anomalier, før de eskalerer til større fejl
- Pålidelig dataflow mellem systemer, især i integrationstunge miljøer
I sundhedspleje handler overvågning ikke kun om infrastrukturoverlevelse. Det handler om at opretholde integriteten af kliniske arbejdsgange, hvor timing, nøjagtighed og datatilgængelighed direkte påvirker resultaterne.
Forbedring af Patient Sikkerhed med AWS CloudWatch
Overvågning og alarmering i sundhedssystemer spiller en kritisk rolle i opretholdelsen af patientsikkerhed ved at sikre, at data er tilgængelige, nøjagtige og leveres til tiden. I praksis kræver dette at spore specifikke systemadfærdsmønstre og reagere på fejl straks.
Elektroniske Sundhedsoptegnelser (EHR)
For EHR-systemer afhænger kontinuerlig adgang til patientdata af stabiliteten af backend-tjenester og databaser.
- Hvad overvåges: API-latens, databaseresponstid, fejlrater
- Type af alarm: Tærskelbaserede alarmer ved latenspikes og stigning i fejlrater
- Eksempler på udløsere: API-responstid overskrider definerede grænser, databasen forespørgsler langsommere, eller fejlrater stiger over normale niveauer
Overvågning af disse metrikker sikrer uafbrudt adgang til patientjournaler og forhindrer forsinkelser i kliniske beslutninger.
Kliniske Beslutningsstøttesystemer (CDSS)
CDSS-platforme er afhængige af rettidig behandling af kliniske regler og sømløs dataudveksling med eksterne systemer.
- Hvad overvåges: Regelbehandlingstid, integrationsstatus med laboratorie systemer, systemudførelsesforsinkelser
- Type af alarm: Begivenhedsbaserede og latensalarmer til forsinket eller mislykket behandling
- Eksempler på udløsere: Forsinket udførelse af kliniske regler, mislykkede API-opkald til laboratorie systemer, eller manglende inputdata
Alarmer kan udløses, når kliniske regler ikke behandles til tiden, eller når integrationer fejler, hvilket mindsker risikoen for oversete anbefalinger eller forkerte behandlingsbeslutninger.
Fjernpatientovervågning (RPM)
RPM-systemer er afhængige af kontinuerlig dataflow fra medicinske enheder og realtidsanalyse af patientvitaler.
- Hvad overvåges: Enhedens forbindelse, dataindsamlingshastighed, unormale vitalgrænser
- Type af alarm: Realtidsalarmer for manglende data eller unormale patientmetrikker
- Eksempler på udløsere: Enhed frakobles, fald i datatransmissionsfrekvens, eller vitaler overstiger foruddefinerede grænser
Disse alarmer sikrer, at plejeteams straks underrettes om både tekniske problemer og potentielle patientrisici, hvilket muliggør hurtigere indgriben.
Omkostningsoptimering og Effektivitet med AWS CloudWatch
Cloud-omkostninger kan vokse hurtigt i sundhedsmiljøer, hvis de ikke håndteres. I AWS CloudWatch sundhedsmiljøer afhænger omkostningsoptimering af synlighed ind i specifikke omkostningsdrivere snarere end generel systemydelse.
I praksis betyder dette at identificere, hvor omkostninger genereres, og optimere systemadfærd baseret på reelle brugs mønstre.
De mest almindelige omkostningsdrivere i AWS-baserede sundhedssystemer inkluderer:
- Lambda eksekveringsvarighed — længere eksekveringstider øger direkte compute-omkostningerne
- Invokationsantal — højfrekvente triggers (især i hændelsesdrevede systemer) kan betydeligt øge det samlede forbrug
- Logvolumen — overdreven eller uskstructured logning fører til høje lager- og indtagningsomkostninger
- Metriklagring — store mængder af tilpassede metrikker, især med høj granularitet, kan øge overvågningsudgifterne
CloudWatch giver detaljerede indsigt i disse områder, hvilket giver teams mulighed for at spore brugs mønstre og foretage målrettede optimeringer.
I stedet for bredt at analysere systemadfærd kan teams identificere præcist, hvor omkostningerne genereres, og tage handling, såsom at reducere Lambda eksekveringstiden, begrænse unødvendige invokationer eller optimere logningsstrategier.
Eksempel fra praksis
For eksempel opdagede vi, at visse AWS Lambda-funktioner i et af vores sundhedsprojekter forbrugte op til $300 om måneden. Ved at analysere CloudWatch-metrikker optimerede vi funktionerne og reducerede omkostningerne til kun $20–30—hvilket resulterede i besparelser på næsten $1.000.
De største omkostningsdrivere, vi typisk ser, er ineffektiv Lambda eksekveringstid, overdreven logning og uoptimale genforsøgningsmekanismer.
Hvad er AWS CloudWatch?
Amazon CloudWatch er en overvågnings- og observabilitetstjeneste designet til at give realtidsindsigt i applikationer, infrastruktur og systemadfærd.
I sundhedssystemer, hvor flere tjenester, integrationer og dataflows opererer samtidigt, fungerer CloudWatch som et centraliseret lag, der indsamler og korrelerer operationelle data på tværs af hele systemet.
CloudWatch opererer på tværs af tre hovedlag — metrikker, logs og hændelser — som sammen muliggør fuld observabilitet af distribuerede systemer.
Det aggregerer tre kerne typer data:
- Metrikker — præstationsindikatorer såsom latenstid, CPU-udnyttelse, fejlrater og anmodningsvolumen
- Logs — detaljerede optegnelser over systemhændelser, applikationsadfærd og fejl
- Hændelser — systemændringer, triggers og automatiserede svar
Dette samlede udsigt giver teams mulighed for at opdage problemer hurtigere, forstå deres rodårsag og reagere, før de påvirker kliniske arbejdsprocesser.
CloudWatch er ikke bare et overvågningsværktøj, men et operationelt kontrol lag, der muliggør:
- Realtidssystemsynlighed på tværs af distribuerede sundhedsapplikationer
- Proaktiv problemopdagelse gennem tærskler og anomalidetektion
- Automatiserede svar på systemhændelser (f.eks.
I komplekse sundhedsmiljøer, hvor systemer omfatter EHR-platforme, IoT-enheder, API'er og tredjepartsintegrationer, er dette niveau af synlighed essentielt for at opretholde systemets pålidelighed og dataintegritet. Som et resultat bliver CloudWatch en nøglekomponent i sundhedsovervågning i moderne cloud-baserede systemer.
5Nøglefunktioner ved CloudWatch for Sundhedsvæsenet
CloudWatch tilbyder et sæt af kernefunktioner, der understøtter sundhedsovervågning, hurtig hændelsesrespons og operationel kontrol i sundhedssystemer.
Automatiserede Advarsler og Notifikationer
Hvad det gør:
CloudWatch udløser advarsler, når foruddefinerede tærskler eller anomalimønstre opdages, og informerer teams via integrerede kommunikationskanaler.
Hvorfor det er vigtigt i sundhedsvæsenet:
Muliggør øjeblikkelig reaktion på kritiske problemer som API-fejl, høj latens eller uautoriserede adgangsforsøg, før de påvirker kliniske arbejdsgange eller patientpleje.
Eksempel:
For eksempel kan en advarsel udløses, når fejlrate overstiger en defineret tærskel, eller når uautoriserede adgangsforsøg opdages, hvilket giver teams mulighed for at reagere, før sikkerhed eller dataintegritet kompromitteres.
Integration med AWS Lambda
Hvad det gør:
CloudWatch integreres med AWS Lambda for at udløse automatiserede handlinger som svar på systembegivenheder, såsom at prøve mislykkede processer igen, genstarte tjenester eller skalere infrastruktur.
Hvorfor det er vigtigt i sundhedsvæsenet:
Understøtter automatiseret hændelsesrespons, hvilket giver systemer mulighed for selvheling uden manuel indblanding. Dette er især vigtigt i tidsfølsomme miljøer, hvor forsinkelser i respons kan forstyrre plejeleveringen.
Eksempel:
For eksempel, hvis en databehandlingsfunktion fejler, kan CloudWatch automatisk udløse en genprøve- eller genstartsmechanisme, hvilket sikrer, at kritiske patientdata behandles uden manuel indblanding.
AI-Drevet Anomalidetektion
Hvad det gør:
CloudWatch bruger maskinlæringsmodeller til at registrere usædvanlige mønstre i systemadfærd, selv når der ikke er defineret faste tærskler.
Hvorfor det er vigtigt i sundhedsvæsenet:
Hjælper med at opdage unormal systemadfærd, såsom uventede stigninger i API-brug eller fald i data fra medicinske enheder, hvilket muliggør proaktiv problemløsning, før det påvirker patientpleje.
Eksempel:
For eksempel kan et pludseligt fald i indkommende data fra tilsluttede medicinske enheder signalere en enhedsfejl eller forbindelsesproblemer, hvilket giver teams mulighed for at undersøge, før patientovervågning påvirkes.
6Sådan fungerer AWS CloudWatch
CloudWatch fungerer som en kontinuerlig overvågningscyklus, der indsamler, behandler og handler på systemdata i realtid. Denne proces kan repræsenteres som en sløjfe bestående af fire nøglefaser:
Indsaml
CloudWatch indsamler metrikker og logfiler fra AWS-ressourcer, applikationer og tilsluttede systemer, herunder servere, API'er, databaser og IoT-enheder.
Overvåg
De indsamlede data visualiseres gennem dashboards, hvilket giver teams mulighed for at følge systemadfærd, korrelere metrikker og logfiler samt identificere præstationsproblemer eller anomalier.
Handle
Når foruddefinerede grænseværdier overskrides, eller usædvanlige mønstre opdages, aktiverer CloudWatch alarmer eller automatiserede svar, såsom at skalere infrastrukturer eller genstarte tjenester.
Analyser
CloudWatch muliggør dybere analyse af systemadfærd ved hjælp af historiske data, højopløste metrikker og værktøjer som Metric Math for at identificere trends og optimere ydeevnen.
Ifølge dette flow muliggør CloudWatch en fuldt automatiseret overvågningsproces, hvor data kontinuerligt indsamles, analyseres og bruges til at udløse handlinger.
I sundhedssystemer er denne cyklus kritisk, fordi den muliggør automatisk registrering af anomalier, såsom unormal API-latens eller fejl i databehandling. Disse problemer kan straks udløse alarmer og automatiserede skalerings- eller genopretningshandlinger uden manuel intervention, hvilket sikrer, at kliniske systemer forbliver lydhøre og pålidelige. Denne tilgang er essentiel for effektiv overvågning i sundhedssystemer og realtidsalarmering, hvor øjeblikkelig respons er påkrævet.
7Case Study: AWS CloudWatch i en Sundhedsmæssig Sammenhæng
Lad os undersøge, hvordan AWS CloudWatch til sundhedsprojekter blev implementeret i et af vores sundhedsprojekter — en platform til overvågning af patienter på afstand, der blev brugt af klinikker og patienter.
Projektkontekst
- Bygget på AWS-infrastruktur
- Over 500 AWS Lambda-funktioner
- To platforme: web (til praktikere) og mobil (til patienter)
- 20.000+ brugere på tværs af platforme
- 500+ loggrupper og 1.400+ overvågede metrikker
Dette var et høj-belastnings, realtids system med kontinuerlig databehandling, hvor patientdata, enheds-signaler og systembegivenheder blev behandlet uden afbrydelse.
Dataincollection og Visualisering
Vi indsamler store mængder logfiler, metrikker og begivenheder fra flere AWS-tjenester, herunder:
- API Gateway — anmodningsrater, latens, fejlbesvarelser
- AWS Lambda — udførelsesvarighed, anmodningsantal, fejlprocenter
- DynamoDB — læse/skrive kapacitetsbrug, throttling-begivenheder
CloudWatch konsoliderer disse data til et centralt dashboard, som giver realtidsvisibilitet i systemadfærd.
Dette gør det muligt for teams hurtigt at identificere:
- ydeevnebottlenecks
- fejlende tjenester
- unormal systemadfærd
og spore problemer tilbage til deres præcise kilde.
Advarselskonfiguration, målinger og begivenheder
Vi har konfigureret advarsler baseret på kritiske systemgrænser og realtidsbegivenheder.
Eksempler på advarsler inkluderer:
- Forsinkelsesadvarsler udløst, når API svartiden overskrider definerede grænser (f.eks. >300–500 ms)
- Fejlrateadvarsler aktiveret, når fejlraterne overskrider acceptable niveauer (f.eks. >2–5%)
- Advarsler om uautoriseret adgang udløst ved mistænkelige autentificeringsforsøg eller usædvanlige adgangsmønstre
Disse advarsler kan defineres i koden eller konfigureres direkte i CloudWatch.
Målinger og begivenheder bruges også til at automatisere systemadfærd, såsom:
- skalering af infrastruktur under øget belastning
- udløse meddelelser til operationelle teams
- initiere genoprettelseshandlinger for mislykkede processer
Indvirkning
Med denne opsætning opnåede systemet:
- Hurtigere opdagelse og løsning af ydeevneproblemer
- Reduceret nedetid i patientvendte tjenester
- Forbedret pålidelighed af realtidsdatabehandling
- Bedre kontrol over infrastrukturens adfærd under belastning
Vigtigst af alt sikrede overvågningssystemet, at kritiske sundhedsarbejdsgange forblev stabile og reaktive, selv under høj belastning og kontinuerlige datastreams.
8Eksempler på CloudWatch-brug i vores sundhedsprojekt
Lad os tage et nærmere kig på, hvordan CloudWatch fungerer inden for det sundhedsprojekt, vi tidligere har præsenteret.
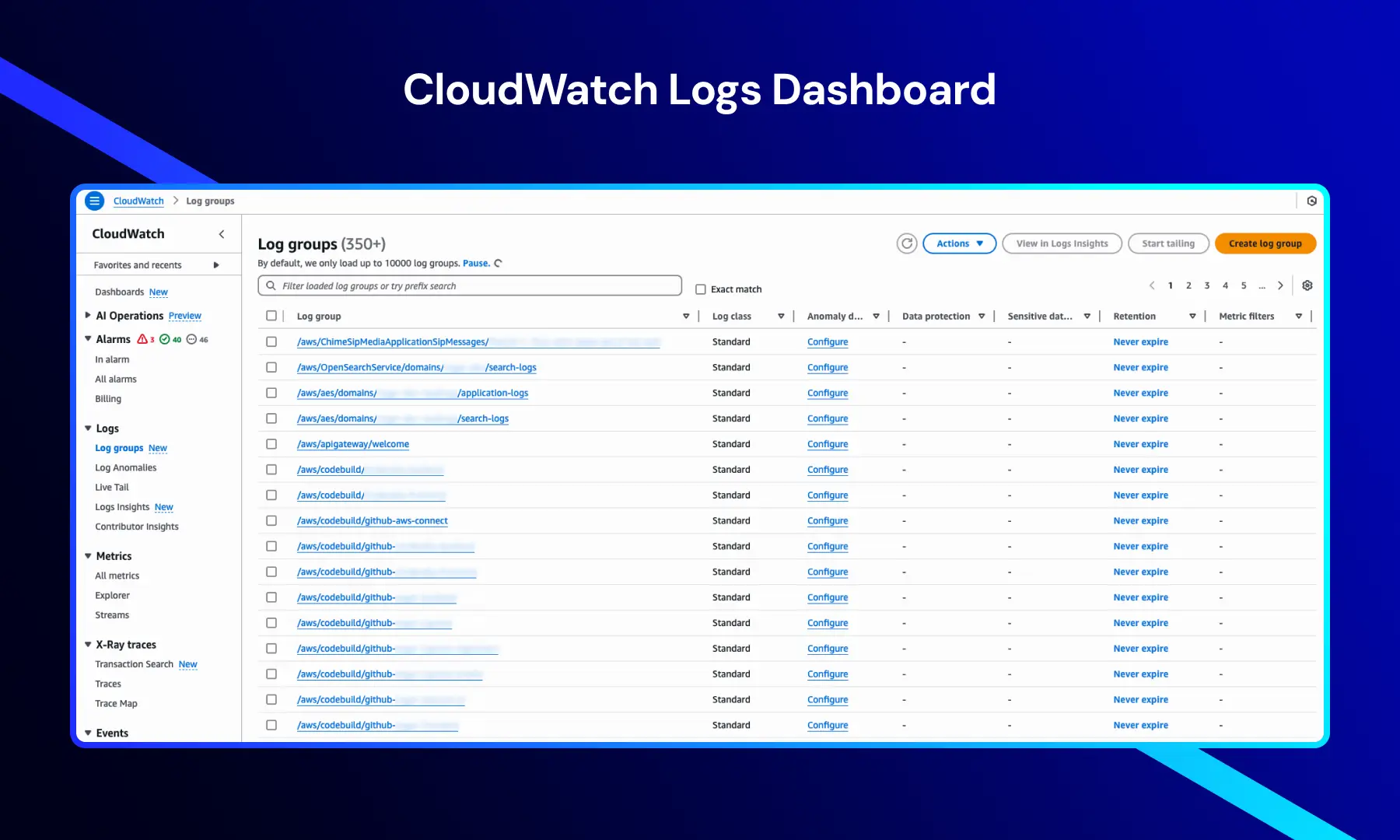
CloudWatch Logs Dashboard
Denne visning viser loggrupper, der organiserer og gemmer logs fra forskellige AWS-tjenester og -ressourcer.
Det giver nøgleinformation såsom:
- Loggruppe-navne — logs genereret af applikationer, infrastruktur og AWS-tjenester
- Logklasse — typisk indstillet til Standard for standard loghåndtering
- Bevaringsindstillinger — ofte konfigureret til "Aldrig udløbe" til langvarig analyse
- Anomali-detekteringskonfiguration — muliggør identifikation af usædvanlige logmønstre
Navigationsmuligheder såsom Alarmer, Målinger, X-Ray-spor og Begivenheder giver adgang til de fulde overvågnings- og analysefunktioner i CloudWatch.
Denne visning er essentiel for centraliseret logstyring og effektiv fejlfinding på tværs af distribuerede systemer.
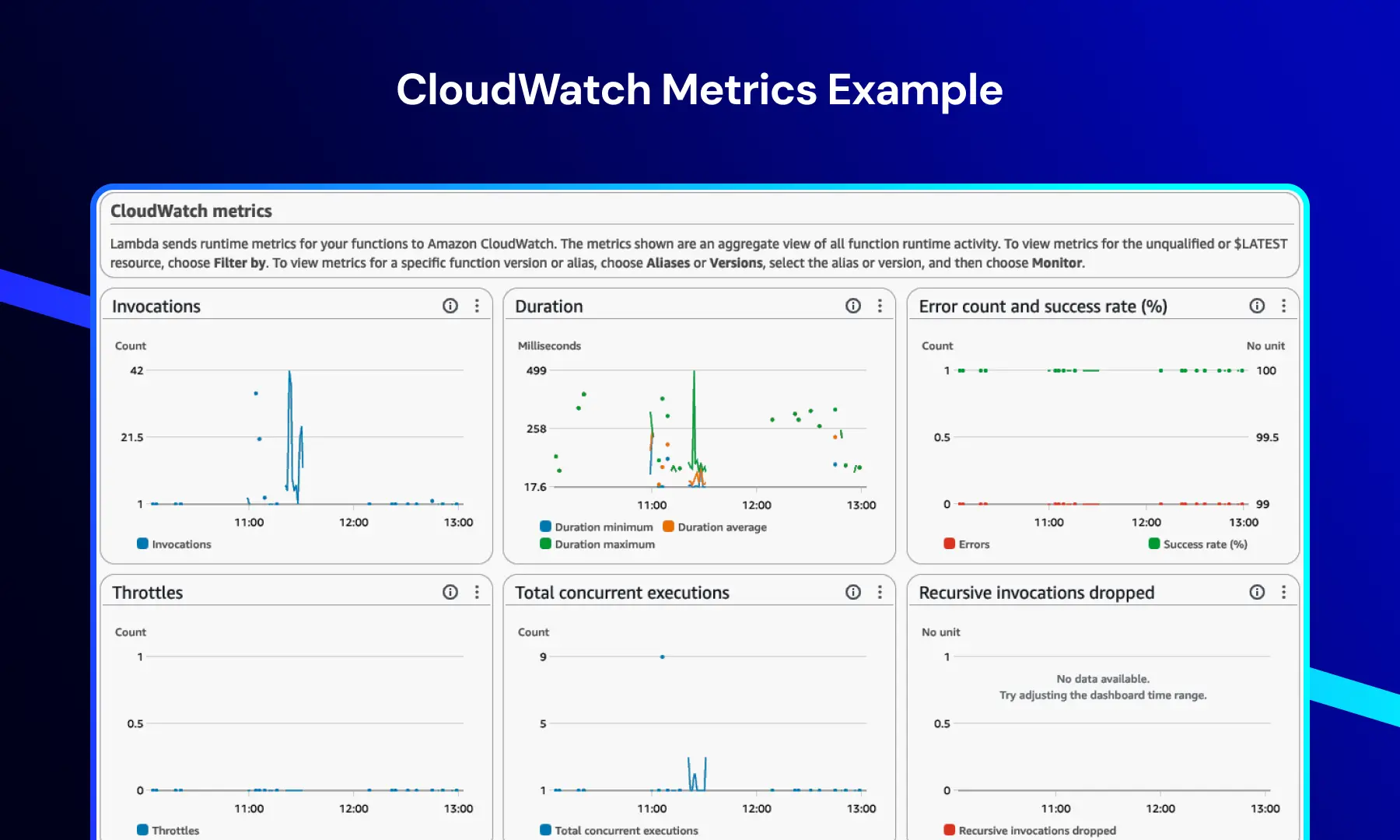
CloudWatch Metrics
Denne dashboard giver realtidsindsigt i system- og applikationsydelse.
Det inkluderer typisk:- Funktionskald
- Udførelsestid
- Fejlrater
- Dæmpningsbegivenheder
Dette gør det muligt for teams at overvåge præstationstrends, opdage flaskehalse og opretholde systemets stabilitet under belastning.
Lambda Funktionsmålinger
Dette dashboard fokuserer på detaljerede præstationsmålinger for AWS Lambda-funktioner.
Nøgleindsigter inkluderer:
- De dyreste kald — identificering af funktioner med det højeste ressourceforbrug
- Udførelsestid vs. faktureret tid — forståelse af omkostningsadfærd baseret på AWS faktureringsregler
- Adgang til detaljerede logfiler — muliggør hurtig fejlfinding og optimering af præstation
Dette niveau af synlighed er kritisk for at optimere både ydeevne og infrastrukturomkostninger i begivenhedsdrevne sundhedssystemer.

![Cloud Software Development [AWS].webp](/static/Cloud_Software_Development_AWS_a351611d38.webp) 9
9Fordele ved AWS CloudWatch for Sundhedsvæsenet
CloudWatch giver sundhedssystemer den synlighed og kontrol, der er nødvendig for at opretholde ydeevne, pålidelighed og sikkerhed i komplekse, realtidsmiljøer.
Nøglefordele inkluderer:
Fuldt observabilitet på tværs af systemer
CloudWatch muliggør end-to-end sundhedsovervågning på tværs af API'er, databaser, infrastruktur og tilsluttede medicinske enheder, hvilket gør det muligt for teams at forstå systemadfærd i realtid og hurtigt identificere anomalier.
Hurtigere hændelsesrespons
Automatiserede advarsler og overvågning i realtid reducerer responstiden, hvilket hjælper teams med at opdage og løse problemer, inden de påvirker kliniske arbejdsgange eller patientpleje.
Reduceret nedetid
Tidlig opdagelse af anomalier og automatiserede genoprettelseshandlinger minimerer serviceafbrydelser i kritiske sundhedssystemer.
Forbedret operationel effektivitet
Klart syn på systempræstationen gør det muligt for teams at optimere ressourceforbruget og opretholde stabil systemadfærd under varierede belastningsforhold.
Forbedret overholdelse og sikkerhed
Kontinuerlig overvågning og logning understøtter revisionskrav og hjælper med at opdage uautoriseret adgang eller usædvanlig systemaktivitet.
Skalerbarhed
CloudWatch skalerer med systemvækst, understøtter stigende datamængder, brugere og tilsluttede enheder uden tab af synlighed.
10Er det muligt ikke at bruge CloudWatch?
Ja, der findes alternativer til CloudWatch, og i nogle tilfælde kan de være mere passende afhængigt af systemarkitektur og teampræferencer.
Almindelige alternativer inkluderer:
- Datadog — tilbyder avancerede overvågningsmuligheder med en stærk brugergrænseflade og righoldige visualiseringsværktøjer
- Prometheus + Grafana — open-source løsning, der giver fleksibel metrisk indsamling og visualisering, ofte brugt i tilpassede eller multi-cloud miljøer
- Elastic Stack (ELK) — fokuseret på centraliseret logstyring og søgemuligheder
- New Relic — giver fuld stak observabilitet med stærk støtte til overvågning af applikationsydelse
Valget afhænger dog i høj grad af, hvor tæt dit system er integreret med AWS.
Sammenligningsoversigt
Værktøj Nøglefordel Handelsbalancer Datadog Bedre UI og brugeroplevelse Højere omkostninger i skala Prometheus Meget fleksibel og tilpasselig Kompleks opsætning og vedligeholdelse CloudWatch Bedste pasform til AWS-native systemer Begrænset fleksibilitet uden for AWS CloudWatch forbliver et praktisk valg for AWS-baserede sundhedssystemer på grund af sin native integration, lavere driftsomkostninger og problemfri skalerbarhed.
For teams, der opererer fuldt ud inden for AWS, reducerer det behovet for yderligere værktøjer og forenkler overvågningsarkitekturen uden at kompromittere synlighed eller kontrol.
11Implementeringstrin for AWS CloudWatch
Implementering af CloudWatch i sundhedssystemer kræver ikke kun korrekt opsætning, men også en struktureret tilgang for at undgå almindelige faldgruber, der kan påvirke ydeevne, omkostninger og pålidelighed.
1. Opsætning af overvågning
Aktivér CloudWatch for alle relevante AWS-tjenester og definer de nøgledimensioner, der afspejler systemets sundhed og ydeevne.
- Konfigurer overvågning for API'er, databaser, compute-tjenester og integrationer
- Installer CloudWatch-agenter, hvor det er nødvendigt (f.eks. til tilpassede servere)
- Fokuser på kritiske dimensioner som latens, fejlrate og systembelastning
Bedste praksis:
Start med et minimalt, men meningsfuldt sæt af dimensioner knyttet til reelle systemrisici (f.eks. API-latens, fejlede anmodninger, datadelae).
Hvad man ikke skal gøre:
Undgå at spore for mange dimensioner fra starten — dette skaber støj, øger omkostningerne og gør det sværere at identificere reelle problemer.
2. Konfigurer dashboards og alarmer
Opret dashboards og alarmer, der afspejler reelle driftsprioriteter snarere end generiske systemdimensioner.
- Byg dashboards til nøglearbejdsgange (f.eks., patient data flow, API performance)
- Indstil alarmer for latenstid, fejlrate og unormal systemadfærd
- Definér tærskler baseret på virkelig systembrug, ikke antagelser
bedste praksis:
Justér alarmer i forhold til forretningskritiske scenarier, såsom forsinket adgang til patientjournaler eller fejlet datalevering.
Hvad ikke at gøre:
Undgå alt for følsomme alarmer eller dårligt definerede tærskler — dette fører til alarmtræthed og ignorerede meddelelser.
3. Automatiser svar
Brug CloudWatch-integrationer til at automatisere systemreaktioner på hændelser.
- Udløs AWS Lambda-funktioner for genforsøg, skalering eller genopretning
- Konfigurer automatisk skalering baseret på belastnings- og præstationsmålinger
- Integrer meddelelser med hændelsesstyringsværktøjer
Bedste praksis:
Automatiser svar på forudsigelige fejl (f.eks. genforsøg af midlertidige fejl, skalering under trafiktoppe).
Hvad ikke at gøre:
Stol ikke udelukkende på manuel indgriben — i sundhedssystemer kan forsinkede svar direkte påvirke systemets pålidelighed.
4. Test og optimer kontinuerligt
Overvågning er ikke en engangsintegration — det kræver regelmæssig testning og optimering.
- Valider, at alarmer udløses korrekt
- Simuler fejlscenarier (f.eks. API-nedetid, databesvær)
- Gennemgå og juster regelmæssigt tærskler, målinger og alarmlogik
Bedste praksis:
Forfin kontinuerligt overvågning baseret på reelle hændelser og systemadfærd.
Hvad ikke at gøre:
Undgå en "sæt og glem" tilgang — forældede konfigurationer overser ofte kritiske problemer eller genererer irrelevante alarmer.
12Konklusion
AWS CloudWatch er et praktisk valg til overvågning af sundhedssystemer i AWS-miljøer, der giver den synlighed, alarmering og omkostningskontrol, der kræves for produktionsmiljøer.
I komplekse sundhedsmæssige arkitekturer, hvor flere tjenester, integrationer og realtidsdataflows skal fungere pålideligt, gør CloudWatch det muligt for teams at opretholde stabilitet, opdage problemer tidligt og reagere uden forsinkelse.
Når det implementeres korrekt, understøtter det fuld observabilitet, hurtigere hændelsesrespons og en mere forudsigelig systemadfærd under belastning.
Når sundhedssystemer fortsætter med at skalere og blive mere datadrevne, er det ikke længere valgfrit at have en veldefineret overvågnings- og alarmeringsstrategi — det er en kernekomponent i opbygningen af pålidelig og vedligeholdelig software.
Hvis du designer eller skalerer en sundhedsplatform på AWS, kan en godt konfigureret CloudWatch-opsætning signifikant reducere driftsrisici og forbedre systemets ydeevne.
13Har du brug for hjælp til at implementere CloudWatch i dit sundhedsprojekt?
Hos JetBase hjælper vi sundhedsteams med at designe overvågningssystemer, der går ud over grundlæggende opsætning — med fokus på pålidelighed, omkostningseffektivitet og virkelighedens ydeevne.
Uanset om du bygger en ny platform eller optimerer en eksisterende, kan vi hjælpe dig med at opsætte en overvågningsstrategi, der passer til din arkitektur og dine forretningsmål.
Kontakt os for at drøfte dit projekt eller få en konsultation.