Explorar los pros y los contras de la arquitectura sin servidor revela cómo está remodelando la forma en que las empresas despliegan y gestionan aplicaciones. Este modelo de computación en la nube elimina la necesidad de gestionar servidores, permitiendo que los equipos se centren en construir y entregar características del producto en lugar de manejar la infraestructura.
Entender los beneficios de la arquitectura sin servidor y sus desventajas es esencial para los equipos que eligen el enfoque en la nube adecuado.
En la práctica, la arquitectura sin servidor se elige con mayor frecuencia en escenarios donde la velocidad, la flexibilidad y el control de costos son críticos. Se utiliza comúnmente para el desarrollo de MVP, sistemas impulsados por eventos y aplicaciones con tráfico impredecible o de ráfaga. En estos casos, los equipos pueden lanzar más rápido, escalar automáticamente y evitar inversiones iniciales en infraestructura.
No obstante, la arquitectura sin servidor no es una solución universal. Su efectividad depende del tipo de carga de trabajo, la arquitectura del sistema y la estrategia de escalado a largo plazo. En algunos casos, puede introducir limitaciones de rendimiento, costos más altos a gran escala o un control reducido sobre el entorno.
Este artículo es para CTOs, fundadores y equipos de producto que están evaluando la arquitectura sin servidor y necesitan una comprensión clara y práctica de cuándo tiene sentido usarla.
¿Qué es la Arquitectura Sin Servidor?
La arquitectura sin servidor es un modelo de computación en la nube donde el proveedor de la nube gestiona la infraestructura subyacente, lo que permite a los equipos de desarrollo centrarse completamente en la lógica de la aplicación en lugar de la gestión de servidores.
A pesar de su nombre, sin servidor no significa que los servidores no existan. Significa que la provisión, escalado y mantenimiento de la infraestructura son manejados por proveedores como AWS, Google Cloud o Microsoft Azure. Los desarrolladores despliegan código en forma de funciones, que se ejecutan solo cuando se necesitan.
Este modelo a menudo se denomina Función como Servicio (FaaS) y se utiliza comúnmente en aplicaciones modernas y nativas de la nube que requieren flexibilidad, escalabilidad y ciclos de entrega más rápidos.
Estas características explican por qué la arquitectura sin servidor es ampliamente adoptada en el desarrollo de productos moderno, especialmente para equipos que priorizan la velocidad, la escalabilidad y la reducción de la carga operativa.
Cómo Funciona la Arquitectura Sin Servidor
Las aplicaciones sin servidor se construyen en torno a eventos y ejecuciones de funciones de corta duración. En proyectos del mundo real, las funciones sin servidor son típicamente activadas por:
- solicitudes de API (puntos finales HTTP)
- cambios en la base de datos (por ejemplo, nuevo registro, actualización)
- subidas de archivos (por ejemplo, , imágenes, documentos)
- trabajos programados (tareas cron)
- colas de mensajes y sistemas de streaming
Una vez que se produce un desencadenante, el flujo es el siguiente:
- El evento es recibido por el proveedor de la nube
- Se invoca una función en respuesta a ese evento
- La función se ejecuta en un entorno aislado
- Procesa la solicitud y devuelve un resultado
- El entorno de ejecución se termina después de completar la tarea
Esto se conoce como un tiempo de ejecución efímero: las funciones no se ejecutan continuamente, sino que se crean bajo demanda y se destruyen tras la ejecución. Desde una perspectiva empresarial, esto impacta directamente en costos y escalabilidad. Los equipos solo son facturados por el tiempo de ejecución real, generalmente medido en milisegundos. Sin embargo, la facturación puede volverse menos predecible si:
- las funciones se desencadenan con demasiada frecuencia
- el tiempo de ejecución no está optimizado
- los procesos en segundo plano están mal diseñados
Características Centrales de la Arquitectura Sin Servidor
La arquitectura sin servidor se define por varios principios fundamentales que modelan cómo se diseñan y operan los sistemas.
Arquitectura impulsada por eventos
Las aplicaciones reaccionan a eventos en lugar de ejecutarse continuamente. En la práctica, esto significa que los sistemas están compuestos de pequeñas funciones independientes activadas por acciones de los usuarios, cambios en el sistema o integraciones externas.
Ejecución sin estado
Cada ejecución de función es independiente y no almacena datos entre ejecuciones. Cualquier estado requerido debe almacenarse externamente (por ejemplo, bases de datos, servicios de almacenamiento). Esto mejora la escalabilidad, pero introduce complejidad adicional en la gestión de datos y flujos de trabajo.
Infraestructura administrada
El proveedor de la nube se encarga de:
- provisionamiento de servidores
- escalado
- parches y mantenimiento
- alta disponibilidad
Sin embargo, los equipos de desarrollo siguen siendo responsables de:
- lógica de aplicación
- diseño de arquitectura
- configuraciones de seguridad
- monitoreo y control de costos
Escalado automático
Las plataformas sin servidor escalan automáticamente las funciones en función de las solicitudes entrantes. Esto permite que los sistemas manejen picos de tráfico sin intervención manual. Al mismo tiempo, el escalado no controlado puede llevar a:
- costos inesperados
- alcanzar límites de concurrencia
- cuellos de botella de rendimiento en servicios posteriores (por ejemplo, bases de datos)
Los Beneficios de la Arquitectura Sin Servidor
Al explorar las ventajas y desventajas de la arquitectura sin servidor, es importante comprender que sus beneficios dependen en gran medida del tipo de carga de trabajo y del diseño del sistema.
Estas ventajas de servidores y beneficios de la computación sin servidor se hacen evidentes cuando se aplican en los escenarios adecuados.
Bloqueo del proveedor
Las soluciones sin servidor están estrechamente acopladas a los ecosistemas de proveedores de la nube (por ejemplo, AWS Lambda, Azure Functions, Google Cloud Functions). Esto crea una dependencia de los servicios, las API y las configuraciones específicas de cada proveedor. En la práctica, esto hace que la migración entre proveedores sea compleja y costosa. Las estrategias de mitigación comunes incluyen:
- usar Infraestructura como Código (IaC) (por ejemplo, Terraform) para estandarizar implementaciones
- abstractar la lógica empresarial de los servicios específicos del proveedor
- diseñar sistemas teniendo en cuenta la portabilidad parcial
Sin embargo, evitar completamente el bloqueo a menudo introduce complejidades adicionales, especialmente en configuraciones de múltiples nubes, que requieren más esfuerzo y coordinación técnica.
Problemas de rendimiento
Las aplicaciones sin servidor pueden experimentar variabilidad en el rendimiento, particularmente debido a los inicios en frío. Un inicio en frío ocurre cuando se invoca una función después de un período de inactividad, lo que requiere que la plataforma inicialice un nuevo entorno de ejecución. La demora puede variar según:
- el tiempo de ejecución (por ejemplo, Node.js vs Java)
- el tamaño de la función y sus dependencias
- la configuración del proveedor de la nube
Esto puede impactar aplicaciones sensibles a la latencia. Los enfoques de mitigación comunes incluyen:
- concurrencia provisionada (mantener las funciones cálidas)
- optimizar el tamaño de la función y sus dependencias
- usar funciones en el borde cuando sea aplicable
Monitoreo y depuración
El monitoreo de sistemas sin servidor es más complejo que en arquitecturas tradicionales debido a su naturaleza distribuida y efímera. Los desafíos incluyen:
- falta de entornos de ejecución persistentes
- dificultad para rastrear solicitudes a través de múltiples funciones
- visibilidad limitada en el comportamiento en tiempo de ejecución
Para abordar esto, los equipos necesitan:
- herramientas de trazado distribuido (por ejemplo, AWS X-Ray, OpenTelemetry)
- sistemas de registro centralizados
- prácticas avanzadas de observabilidad
Sin las herramientas adecuadas, identificar problemas de rendimiento o fallas se vuelve significativamente más difícil.
Control limitado sobre el entorno
Las plataformas sin servidor abstraen la infraestructura, lo que reduce el esfuerzo operativo pero también limita el control. Por lo general, los equipos no pueden:
- acceder al sistema operativo subyacente
- personalizar los entornos de ejecución más allá de las opciones predefinidas
- controlar configuraciones de rendimiento de bajo nivel
Estas limitaciones pueden ser problemáticas para:
- aplicaciones con dependencias específicas del sistema
- cargas de trabajo críticas para el rendimiento
- sistemas heredados que requieren entornos personalizados
Gestión compleja del estado
Las funciones sin servidor son sin estado por diseño, lo que significa que no retienen datos entre ejecuciones. Para gestionar el estado, los equipos deben depender de servicios externos como:
- bases de datos (SQL/NoSQL)
- almacenes en memoria (por ejemplo, Redis)
- almacenamiento de objetos (por ej., S3)
Mientras esto permite escalabilidad, también:
- aumenta la complejidad arquitectónica
- introduce latencia adicional
- requiere una gestión cuidadosa de la consistencia de los datos
Impredecibilidad de Costos a Escala
Aunque sin servidor es rentable para cargas de trabajo variables, los costos pueden volverse impredecibles a gran escala. Esto suele ocurrir cuando:
- las funciones se activan con alta frecuencia
- el tiempo de ejecución no está optimizado
- una arquitectura ineficiente lleva a invocaciones excesivas
Debido a que la facturación está vinculada a la ejecución, incluso pequeñas ineficiencias pueden escalar en costos significativos bajo un uso intenso.
Limites de Tiempo de Ejecución
Las plataformas sin servidor imponen límites máximos de tiempo de ejecución para las funciones (por ejemplo, minutos dependiendo del proveedor). Esto crea limitaciones para:
- procesos de larga duración
- tareas de procesamiento de datos intensivas
- flujos de trabajo sincrónicos
Para sortear esto, los equipos a menudo necesitan rediseñar sistemas utilizando:
- flujos de trabajo asincrónicos
- colas de tareas
- encadenamiento de funciones
Preocupaciones de Cumplimiento y Seguridad
En industrias reguladas (por ejemplo, atención médica, fintech), sin servidor introduce desafíos adicionales de cumplimiento. Estos incluyen:
- control limitado sobre la ubicación de la infraestructura y la configuración
- dependencia de las prácticas de seguridad del proveedor
- complejidad para cumplir con estrictos requisitos de gobernanza de datos
Las organizaciones deben asegurarse de que:
- el proveedor de la nube cumpla con los estándares de cumplimiento (por ejemplo, HIPAA, GDPR)
- se implementen políticas adecuadas de control de acceso y manejo de datos
Cuotas Impuestas por el Proveedor
Los proveedores de nube imponen límites (cuotas) sobre el uso sin servidor, incluidos:
- máxima concurrencia
- tasas de solicitud
- asignación de recursos por función
Estos límites suelen ser suficientes para la mayoría de las aplicaciones, pero pueden convertirse en un cuello de botella cuando:
- los sistemas escalan rápidamente
- los picos de tráfico superan los umbrales esperados
- las cuotas no se aumentan de manera proactiva
Sin planificación, esto puede llevar a la limitación y a un rendimiento degradado.
Análisis de Serverless vs. Modelos Tradicionales
Comparar sin servidor con infraestructura tradicional (autogestionada) resalta diferencias fundamentales en cómo se construyen, escalan y mantienen los sistemas, y ayuda a entender mejor los beneficios de la arquitectura sin servidor en sistemas del mundo real. La elección entre estos enfoques depende del tipo de carga de trabajo, la estructura del equipo y consideraciones de costos a largo plazo.
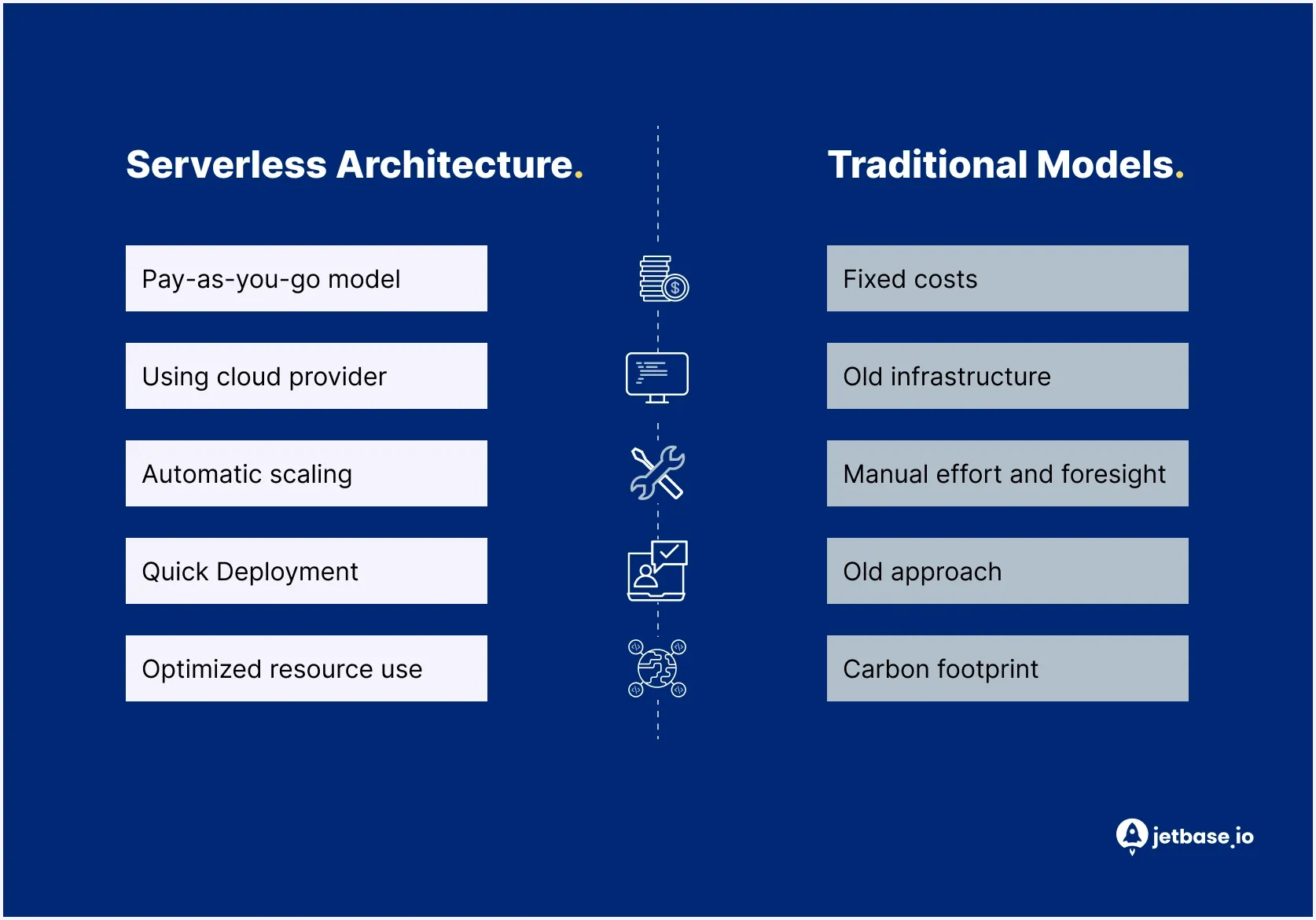
Modelo de Precios
La infraestructura tradicional se basa en recursos provisionados, donde las empresas pagan por la capacidad asignada independientemente del uso real.Esto hace que los costos sean más predecibles, pero a menudo conduce a recursos infrautilizados.
Serverless sigue un modelo de pago por uso, donde la facturación se basa en el tiempo de ejecución real y el número de solicitudes.
En la práctica:
- serverless es más rentable para cargas de trabajo variables o impredecibles
- la infraestructura tradicional suele ser más rentable para cargas de trabajo estables y consistentemente elevadas
Esta comparación muestra claramente cómo los beneficios de serverless difieren según los patrones de carga de trabajo.
Overhead Operativo y Mantenimiento
En configuraciones tradicionales, los equipos son responsables de gestionar:
- servidores y entornos
- configuraciones de escalado
- parches y actualizaciones
Esto requiere un esfuerzo dedicado de DevOps y mantenimiento continuo. Serverless traslada estas responsabilidades al proveedor de la nube, eliminando la gestión de infraestructura y reduciendo el overhead operativo.
Como resultado:
- equipos más pequeños pueden gestionar sistemas complejos
- el esfuerzo de ingeniería se desplaza hacia el desarrollo del producto en lugar del mantenimiento
Escalabilidad y Rendimiento
Escalar en infraestructura tradicional requiere planificación y configuración manual. Los equipos deben aprovisionar recursos por adelantado y ajustar la capacidad según la carga esperada. Serverless escala automáticamente en función de las solicitudes entrantes, permitiendo a los sistemas manejar picos de tráfico sin intervención manual. Sin embargo:
- el escalado serverless está sujeto a límites de concurrencia y del proveedor
- los sistemas tradicionales ofrecen un rendimiento más predecible bajo carga constante
Innovación y Tiempo para el Mercado
La infraestructura tradicional a menudo ralentiza el desarrollo debido a la complejidad de la configuración, la configuración del entorno y las canalizaciones de implementación. Serverless reduce estas barreras al eliminar las dependencias de infraestructura. En la práctica:
- los equipos pueden desplegar más rápido e iterar con más frecuencia
- las startups y los equipos pequeños son los que más se benefician de la reducción del tiempo de configuración
Esto hace que serverless sea particularmente efectivo para el desarrollo de MVP y la experimentación rápida.
Impacto Ambiental
La infraestructura tradicional a menudo conduce al sobre aprovisionamiento, donde los recursos no utilizados aún consumen energía. Serverless optimiza el uso de recursos ejecutando código solo cuando es necesario, lo que puede reducir el consumo total de energía. Sin embargo, el impacto ambiental depende en última instancia de los patrones de carga de trabajo y del diseño del sistema.
Cuándo Elegir Cada Enfoque
Elige serverless cuando:
- estás construyendo un MVP o producto en etapa temprana
- las cargas de trabajo son impulsadas por eventos o impredecibles
- la velocidad de desarrollo es una prioridad
- quieres minimizar la sobrecarga de DevOps
Elige infraestructura tradicional (auto-gestionada o aprovisionada) cuando:
- las cargas de trabajo son estables y consistentemente altas
- la previsibilidad de costos es crítica
- necesitas control total sobre la infraestructura y el tiempo de ejecución
- la consistencia del rendimiento es una prioridad
En última instancia, evaluar los pros y contras de la arquitectura serverless depende de equilibrar costos, escalabilidad y control operativo.
Serverless vs. Microservicios: ¿Cuestión de Elección?
La elección entre serverless y microservicios a menudo se malinterpreta. No son enfoques competitivos, sino conceptos que operan a diferentes niveles. Comprender los pros y contras de la arquitectura serverless es esencial al decidir cómo combinar estos enfoques en sistemas del mundo real.
Los microservicios son un patrón arquitectónico: una manera de estructurar una aplicación como una colección de servicios pequeños e independientes. Serverless, por otro lado, es un modelo de ejecución: una forma de ejecutar y escalar esos servicios sin gestionar la infraestructura.
En la práctica, serverless puede utilizarse para implementar microservicios. Cada función puede representar un servicio pequeño e independiente que responde a eventos específicos, lo que facilita la construcción de sistemas modulares y escalables. Sin embargo, los microservicios no requieren serverless. Los equipos suelen ejecutar microservicios en:
- contenedores (por ejemplo, Kubernetes)
- máquinas virtuales
- infraestructura auto-gestionada o aprovisionada
Cuándo Combinar Serverless y Microservicios
Combinar estos enfoques funciona bien cuando:
- los servicios son impulsados por eventos y débilmente acoplados
- las cargas de trabajo son variables o impredecibles
- los equipos quieren reducir la gestión de infraestructura
En esta configuración, serverless simplifica el despliegue y la escalabilidad, mientras que los microservicios proporcionan una clara separación de preocupaciones.
Cuándo Usar Microservicios Sin Serverless
Ejecutar microservicios en infraestructura aprovisionada puede ser una mejor opción cuando:
- los servicios son de larga duración o con estado
- las cargas de trabajo son estables y consistentemente altas
- los equipos requieren un control detallado sobre el tiempo de ejecución y el rendimiento
Principales Compensaciones a Considerar
Si bien combinar serverless con microservicios ofrece flexibilidad, también introduce complejidad.
Los equipos deben considerar:
- fragmentación del sistema aumentada (muchas funciones/servicios pequeños)
- monitoreo y depuración más complejos
- dependencia de servicios específicos del proveedor
- potencial crecimiento de costos con altos volúmenes de solicitudes
Ejemplos de Arquitectura sin Servidor
La arquitectura sin servidor se utiliza ampliamente en diferentes tipos de aplicaciones, especialmente donde las cargas de trabajo son impulsadas por eventos, variables o requieren una implementación rápida.
A continuación se presentan casos de uso del mundo real que destacan los pros y los contras de la arquitectura sin servidor, mostrando cuándo funciona mejor y qué concesiones deben considerar los equipos.
| Caso de Uso | Problema | Por qué se ajusta sin servidor | Riesgos y Limitaciones |
|---|---|---|---|
| API Backends | Construir APIs escalables requiere gestionar tráfico impredecible, administrar infraestructura y asegurar alta disponibilidad. | Sin servidor permite que las APIs escalen automáticamente según las solicitudes entrantes sin provisionar infraestructura de antemano. Esto facilita el manejo de picos de tráfico y reduce la sobrecarga operativa. |
|
| Webhooks y Procesamiento de Eventos | Los sistemas a menudo necesitan reaccionar a eventos externos (por ejemplo, pagos, acciones de usuarios, integraciones de terceros) en tiempo real. | Las funciones sin servidor pueden ser activadas instantáneamente por eventos entrantes, haciéndolas ideales para el manejo de webhooks y flujos de trabajo impulsados por eventos. |
|
| Tareas Programadas (Cron Jobs) | Las aplicaciones a menudo requieren trabajos en segundo plano recurrentes, como limpieza de datos, generación de informes o sincronización de sistemas. | Las plataformas sin servidor soportan disparadores programados, permitiendo a los equipos ejecutar tareas sin mantener servidores dedicados. |
|
| Canales de Transformación de Datos | Procesar grandes volúmenes de datos (por ejemplo, registros, cargas, eventos analíticos) requiere canales escalables y eficientes. | Sin servidor permite el procesamiento paralelo de flujos de datos y eventos, facilitando la escalabilidad dinámica de los canales según la carga. |
|
| Desarrollo de MVP para Startups | Las startups necesitan lanzarse rápidamente con recursos limitados mientras evitan la inversión inicial en infraestructura. | Serverless permite a los equipos construir y desplegar MVPs sin configurar infraestructura, reduciendo el tiempo de salida al mercado y los costos iniciales. |
|
El Futuro de la Computación Sin Servidor
La computación sin servidor está evolucionando de un enfoque de nicho a un componente central de las arquitecturas modernas en la nube, reflejando tanto las ventajas como desventajas de la arquitectura sin servidor. El enfoque se está desplazando hacia un mejor rendimiento, más control e integración con otras tecnologías.
| Tendencia | Lo que significa en la práctica | Impacto en el negocio |
|---|---|---|
| Computación en el Borde | Las funciones se ejecutan más cerca de los usuarios finales en ubicaciones distribuidas, reduciendo la distancia entre los usuarios y la lógica de procesamiento | Menor latencia, mejora del rendimiento para aplicaciones en tiempo real, mejor experiencia del usuario para productos globales |
| Contenedores Sin Servidor | Las aplicaciones en contenedores se ejecutan en un modelo sin servidor con escalado automático e infraestructura gestionada | Mayor control sobre el tiempo de ejecución y las dependencias, mejor soporte para cargas de trabajo complejas, menos limitaciones que las funciones estándar |
| IA y Procesamiento de Datos | Se utiliza sin servidor para inferencias a demanda, procesamiento de datos impulsado por eventos y canalizaciones automatizadas | Ejecutación de IA rentable, capacidad para escalar el procesamiento de datos dinámicamente, desarrollo más rápido de características basadas en datos |
| Arquitecturas Híbridas | Se combina sin servidor con infraestructura tradicional basada en los requisitos de carga de trabajo | Mejor optimización de costos, diseño de arquitectura más flexible, equilibrio entre escalabilidad y control |
En la práctica, la mayoría de los sistemas modernos combinan estos enfoques en lugar de depender solo de sin servidor.
Estas tendencias destacan aún más cómo los pros y contras de la arquitectura sin servidor evolucionan a medida que la tecnología madura.
¿Estás Listo para Migrar a Sin Servidor?
Adoptar la arquitectura sin servidor no es solo una decisión técnica; requiere evaluar cargas de trabajo, riesgos y escalabilidad a largo plazo, así como entender los pros y contras de sin servidor. Antes de pasar a sin servidor, los equipos deben evaluar si sus sistemas y objetivos se alinean con este modelo.
Lista de Verificación de Preparación para Serverless
Serverless es una buena opción si se aplican la mayoría de las siguientes condiciones:
- cargas de trabajo son impulsadas por eventos (APIs, webhooks, trabajos en segundo plano)
- el tráfico es variable o impredecible
- el sistema no depende de procesos de larga duración
- el tiempo para llegar al mercado es una prioridad
- el equipo quiere reducir la sobrecarga de DevOps
- la arquitectura se puede diseñar como sin estado
Si estas condiciones no se cumplen, serverless puede introducir más complejidad que valor.
Principales Riesgos a Considerar
Antes de adoptar, los equipos deben ser conscientes de los riesgos más comunes:
- crecimiento de costos a escala debido a ejecuciones frecuentes
- variabilidad en el rendimiento (por ejemplo, inicios en frío)
- bloqueo del proveedor y dependencia de los servicios del proveedor
- arquitectura de sistema compleja (especialmente con muchas funciones)
- control limitado sobre el tiempo de ejecución y la infraestructura
Entender estos riesgos temprano ayuda a evitar rediseños costosos más adelante.
Estrategia de Migración Gradual
Una transición exitosa a serverless debe ser incremental en lugar de inmediata.
Un enfoque típico incluye:
- Identificar componentes de bajo riesgo impulsados por eventos
- Migrar cargas de trabajo aisladas (por ejemplo, trabajos en segundo plano, APIs)
- Monitorear rendimiento, costo y confiabilidad
- Expandir el uso de serverless basado en los resultados
Esto reduce el riesgo y permite a los equipos adaptar la arquitectura gradualmente.
Enfoque de Piloto Primero
En lugar de una migración completa, los equipos deben comenzar con un proyecto piloto.
Un piloto sólido es:
- pequeño en alcance pero significativo
- fácil de aislar de los sistemas centrales
- medible en términos de rendimiento y costo
Un piloto exitoso generalmente demuestra:
- reducción de la sobrecarga de infraestructura
- rendimiento estable bajo carga
- comportamiento de costo predecible
Cuándo Evitar Serverless
Serverless puede no ser la opción correcta cuando:
- las cargas de trabajo son de larga duración o intensivas en cálculo
- el tráfico es estable y consistentemente alto
- se requiere control estricto sobre la infraestructura
- la latencia debe ser completamente predecible
En estos casos, las arquitecturas tradicionales o híbridas son a menudo más adecuadas.
En última instancia, las ventajas de serverless dependen de qué tan bien la arquitectura se alinee con sus requisitos específicos de producto y carga de trabajo.
Si está considerando serverless, JetBase puede ayudarte a evaluar el enfoque correcto y planear una transición suave.