Die Erforschung der Vor- und Nachteile von serverloser Architektur zeigt, wie sie die Art und Weise verändert, wie Unternehmen Anwendungen bereitstellen und verwalten. Dieses Cloud-Computing-Modell beseitigt die Notwendigkeit, Server zu verwalten, und ermöglicht es den Teams, sich auf den Aufbau und die Bereitstellung von Produktfunktionen zu konzentrieren, anstatt sich um die Infrastruktur zu kümmern.
Das Verständnis der Vorteile der serverlosen Architektur und ihrer Abwägungen ist entscheidend für Teams, die den richtigen Cloud-Ansatz wählen.
In der Praxis wird die serverlose Architektur häufig in Szenarien gewählt, in denen Geschwindigkeit, Flexibilität und Kostenkontrolle entscheidend sind. Sie wird häufig für MVP-Entwicklungen, ereignisgesteuerte Systeme und Anwendungen mit unvorhersehbarem oder stoßweise Datenverkehr verwendet. In diesen Fällen können Teams schneller starten, automatisch skalieren und Vorabinvestitionen in die Infrastruktur vermeiden.
Allerdings ist serverlos nicht eine universelle Lösung. Ihre Wirksamkeit hängt von der Art der Arbeitslast, der Systemarchitektur und der langfristigen Skalierungsstrategie ab. In einigen Fällen kann sie Leistungsbeschränkungen, höhere Kosten in der Skalierung oder eine reduzierte Kontrolle über die Umgebung einführen.
Dieser Artikel richtet sich an CTOs, Gründer und Produktteams, die die serverlose Architektur bewerten und ein klares, praktisches Verständnis dafür benötigen, wann es sinnvoll ist, sie zu verwenden.
Was ist serverlose Architektur?
Serverlose Architektur ist ein Cloud-Computing-Modell, bei dem der Cloud-Anbieter die zugrunde liegende Infrastruktur verwaltet, sodass Entwicklungsteams sich vollständig auf die Anwendungslogik konzentrieren können, anstatt auf die Serververwaltung.
Trotz des Namens bedeutet serverlos nicht, dass keine Server existieren. Es bedeutet, dass die Bereitstellung, Skalierung und Wartung der Infrastruktur von Anbietern wie AWS, Google Cloud oder Microsoft Azure übernommen werden. Entwickler stellen Code in Form von Funktionen bereit, die nur bei Bedarf ausgeführt werden.
Dieses Modell wird oft als Function as a Service (FaaS) bezeichnet und wird häufig in modernen, cloud-nativen Anwendungen verwendet, die Flexibilität, Skalierbarkeit und schnellere Lieferzyklen erfordern.
Diese Eigenschaften erklären, warum serverlos in der modernen Produktentwicklung weit verbreitet ist, insbesondere für Teams, die Geschwindigkeit, Skalierbarkeit und reduzierte Betriebskosten priorisieren.
Wie funktioniert serverlose Architektur?
Serverlose Anwendungen basieren auf Ereignissen und kurzfristigen Funktionsausführungen. In realen Projekten werden serverlose Funktionen typischerweise durch folgende Ereignisse ausgelöst:
- API-Anfragen (HTTP-Endpunkte)
- Datenbankänderungen (z.B. neuer Datensatz, Aktualisierung)
- Datei-Uploads (z.B.
- Bilder, Dokumente)
- geplante Aufgaben (Cron-Jobs)
- Nachrichtenwarteschlangen und Streaming-Systeme
- Das Ereignis wird vom Cloud-Anbieter empfangen
- Eine Funktion wird als Reaktion auf dieses Ereignis aufgerufen
- Die Funktion wird in einer isolierten Umgebung ausgeführt
- Sie verarbeitet die Anfrage und gibt ein Ergebnis zurück
- Die Ausführungsumgebung wird nach Abschluss beendet
- Funktionen zu häufig ausgelöst werden
- Die Ausführungszeit nicht optimiert ist
- Hintergrundprozesse schlecht gestaltet sind
- Serverbereitstellung
- Skalierung
- Patching und Wartung
- hohe Verfügbarkeit
- Anwendungslogik
- Architekturdesign
- Sicherheitskonfigurationen
- Überwachung und Kostenkontrolle
- unerwarteten Kosten
- Erreichen von Nebenläufigkeitsgrenzen
- Leistungsengpässen in nachgelagerten Diensten (z. B. Datenbanken)
- Verwendung von Infrastructure as Code (IaC) (z. B. Terraform), um Bereitstellungen zu standardisieren
- Abstraktion der Geschäftslogik von anbieter-spezifischen Diensten
- Entwurf von Systemen mit teilweiser Portabilität im Hinterkopf
- Runtime (z. B. Node.js vs. Java)
- Funktionsgröße und Abhängigkeiten
- Konfiguration des Cloud-Anbieters
- bereitgestellte Parallelität (Funktionen warm halten)
- Optimierung der Funktionsgröße und Abhängigkeiten
- Verwendung von Edge-Funktionen, wo anwendbar
- Fehlen von persistierenden Ausführungsumgebungen
- Schwierigkeiten beim Nachverfolgen von Anfragen über mehrere Funktionen hinweg
- Begrenzte Sichtbarkeit des Laufzeitverhaltens
- Verteilte Nachverfolgungswerkzeuge (z. B. AWS X-Ray, OpenTelemetry)
- Zentralisierte Protokollierungssysteme
- Fortgeschrittene Praktiken zur Beobachtbarkeit
- auf das zugrunde liegende Betriebssystem zugreifen
- Ausführungsumgebungen über vordefinierte Optionen hinaus anpassen
- niedrigstufige Leistungs-Konfigurationen steuern
- Anwendungen mit spezifischen Systemabhängigkeiten
- leistungs-kritische Workloads
- Legacy-Systeme, die benutzerdefinierte Umgebungen erfordern
- Datenbanken (SQL/NoSQL)
- In-Memory-Speicher (z. B. Redis)
- Objektspeicher (z. B., S3)
- erhöhter architektonischer Komplexität
- zusätzlicher Latenz
- einem sorgfältigen Management der Datenkonsistenz
- Funktionen mit hoher Frequenz ausgelöst werden
- die Ausführungszeit nicht optimiert ist
- ineffiziente Architekturen zu übermäßigen Aufrufen führen
- langlaufende Prozesse
- umfangreiche Datenverarbeitungsaufgaben
- synchronisierte Workflows
- asynchronen Workflows
- Aufgabenwarteschlangen
- Funktionsverkettung
- eingeschränkte Kontrolle über den Standort und die Konfiguration der Infrastruktur
- Abhängigkeit von den Sicherheitspraktiken des Anbieters
- Komplexität bei der Einhaltung strenger Anforderungen an die Datenverwaltung
- der Cloud-Anbieter die Compliance-Standards erfüllt (z.B. HIPAA, GDPR)
- richtige Zugriffskontroll- und Datenverarbeitungsrichtlinien implementiert sind
- maximale Parallelität
- Anforderungsraten
- Ressourcenzuweisung pro Funktion
- Systeme schnell skalieren
- Verkehrsspitzen die erwarteten Schwellenwerte überschreiten
- Kontingente nicht proaktiv erhöht werden
- Serverless ist kosteneffizienter für variable oder unvorhersehbare Arbeitslasten
- Traditionelle Infrastruktur ist oft kosteneffizienter für stabile, konstant hohe Arbeitslasten
- Servern und Umgebungen
- Skalierungskonfigurationen
- Patches und Updates
- können kleinere Teams komplexe Systeme verwalten
- verschiebt sich der Ingenieureinsatz hin zur Produktentwicklung anstatt zur Wartung
- die Skalierung von Serverless unterliegt den KonkurreJPZNS- und Anbieterlimits
- traditionelle Systeme bieten unter konstanter Last eine vorhersehbarere Leistung
- können Teams schneller bereitstellen und häufiger iterieren
- Startups und kleine Teams profitieren am meisten von der reduzierten Einrichtungszeit
- Sie ein MVP oder ein Produkt in der frühen Phase entwickeln
- Arbeitslasten ereignisgesteuert oder unberechenbar sind
- die Geschwindigkeit der Entwicklung eine Priorität hat
- Sie den DevOps-Aufwand minimieren möchten
- Arbeitslasten stabil und konstant hoch sind
- Kostenvorhersehbarkeit entscheidend ist
- Sie vollständige Kontrolle über Infrastruktur und Laufzeit benötigen
- Leistungsstabilität eine Priorität hat
- Containern (z.B. Kubernetes)
- virtuellen Maschinen
- selbstverwalteter oder bereitgestellter Infrastruktur
- Dienste ereignisgesteuert und lose gekoppelt sind
- Arbeitslasten variabel oder unberechenbar sind
- Teams die Infrastrukturverwaltung reduzieren möchten
- Dienste langlaufend oder zustandsbehaftet sind
- Arbeitslasten stabil und konstant hoch sind
- Teams eine feinkörnige Kontrolle über Laufzeit und Leistung benötigen
- zunehmende Systemfragmentierung (viele kleine Funktionen/Dienste)
- komplexere Überwachung und Fehlersuche
- Abhängigkeit von anbieter-spezifischen Diensten
- potenzielles Kostenwachstum bei hohen Anfragevolumina
- Cold Starts können die Antwortzeiten beeinträchtigen
- Hohes Anfragevolumen kann die Kosten erhöhen
- Concurrency-Limits können die Leistung bei extremer Last beeinträchtigen
- Ereignisausbrüche können eine große Anzahl von Ausführungen auslösen
- Wiederholungen und Fehler müssen sorgfältig behandelt werden
- Fehlersuche in verteilten Ereignisflüssen kann komplex sein
- Ausführungszeitlimits können längere Jobs unterbrechen
- Die Verknüpfung mehrerer Funktionen erhöht die Komplexität
- Überwachungsfehler erfordern zusätzliche Werkzeuge
- Hohes Datenvolumen kann zu signifikanten Kosten führen
- Abhängigkeit von externem Speicher und Diensten erhöht die Latenz
- Komplexe Workflows erfordern Orchestrierung (z. B. Step Functions)
- Die Architektur muss möglicherweise bei großer Skalierung überarbeitet werden
- Die Kosten können mit der Benutzerakzeptanz steigen
- Die Abhängigkeit von Dienstleistungsanbietern kann die Flexibilität später einschränken
- Arbeitslasten sind ereignisgesteuert (APIs, Webhooks, Hintergrundjobs)
- der Traffic ist variabel oder unvorhersehbar
- das System ist nicht auf langlaufende Prozesse angewiesen
- schnelle Markteinführung hat Priorität
- das Team möchte den DevOps-Aufwand reduzieren
- die Architektur kann als zustandslos gestaltet werden
- Kostenwachstum bei Skalierung aufgrund häufiger Ausführungen
- Leistungsvariabilität (z. B. Kaltstarts)
- Anbietersperre und Abhängigkeit von Dienstleistungen des Anbieters
- komplexe Systemarchitektur (insbesondere bei vielen Funktionen)
- begrenzte Kontrolle über Laufzeit und Infrastruktur
- Identifizierung von niederriskanten, ereignisgesteuerten Komponenten
- Migrating isolierte Arbeitslasten (z. B. Hintergrundjobs, APIs)
- Überwachung von Leistung, Kosten und Zuverlässigkeit
- Erweiterung der serverless-Nutzung basierend auf Ergebnissen
- klein im Umfang, aber bedeutend
- einfach von den Kernsystemen isolierbar
- messbar in Bezug auf Leistung und Kosten
- reduzierte Infrastrukturkosten
- stabile Leistung unter Last
- vorhersehbares Kostenverhalten
- Arbeitslasten langlaufend oder rechenintensiv sind
- der Traffic stabil und konstant hoch ist
- strikte Kontrolle über die Infrastruktur erforderlich ist
- die Latenz vollständig vorhersehbar sein muss
Sobald ein Trigger auftritt, sieht der Ablauf folgendermaßen aus:
Dies wird als flüchtige Laufzeit bezeichnet – Funktionen laufen nicht kontinuierlich, sondern werden bedarfsorientiert erstellt und nach der Ausführung gelöscht. Aus geschäftlicher Sicht hat dies direkte Auswirkungen auf Kosten und Skalierbarkeit. Teams werden nur für die tatsächliche Ausführungszeit abgerechnet, die typischerweise in Millisekunden gemessen wird. Allerdings kann die Abrechnung weniger vorhersehbar werden, wenn:
Kernmerkmale der Serverlosen Architektur
Die serverlose Architektur wird von mehreren Kernprinzipien definiert, die die Gestaltung und den Betrieb von Systemen prägen.
Ereignisgesteuerte Architektur
Anwendungen reagieren auf Ereignisse, anstatt kontinuierlich zu laufen. In der Praxis bedeutet dies, dass Systeme aus kleinen, unabhängigen Funktionen bestehen, die durch Benutzeraktionen, Systemänderungen oder externe Integrationen ausgelöst werden.
Zustandslose Ausführung
Jede Funktionsausführung ist unabhängig und speichert keine Daten zwischen Durchläufen. Jeglicher erforderliche Zustand muss extern gespeichert werden (z. B. in Datenbanken, Speicherdiensten). Dies verbessert die Skalierbarkeit, bringt jedoch zusätzliche Komplexität in das Management von Daten und Workflows mit sich.
Verwaltete Infrastruktur
Der Cloud-Anbieter kümmert sich um:
Entwicklungsteams sind jedoch weiterhin verantwortlich für:
Automatische Skalierung
Serverlose Plattformen skalieren Funktionen automatisch basierend auf eingehenden Anfragen. Dadurch können Systeme Verkehrsspitzen ohne manuelles Eingreifen bewältigen. Gleichzeitig kann unkontrollierte Skalierung zu:
Die Vorteile der serverlosen Architektur
Wenn wir die Vor- und Nachteile der serverlosen Architektur untersuchen, ist es wichtig zu verstehen, dass ihre Vorteile stark vom Lasttyp und dem Systemdesign abhängen.
Diese Vorteile der serverlosen Architektur werden deutlich, wenn sie in den richtigen Szenarien angewendet werden.
Vendor Lock-In
Serverless-Lösungen sind eng mit den Ökosystemen der Cloud-Anbieter (z. B. AWS Lambda, Azure Functions, Google Cloud Functions) verbunden. Dies schafft eine Abhängigkeit von anbieter-spezifischen Diensten, APIs und Konfigurationen. In der Praxis macht dies die Migration zwischen Anbietern komplex und kostspielig. Häufige Strategien zur Minderung umfassen:
Jedoch kann die vollständige Vermeidung von Lock-In oft zusätzliche Komplexität einführen, insbesondere in Multi-Cloud-Setups, die mehr Ingenieureffort und Koordination erfordern.
Performance-Probleme
Serverless-Anwendungen können von Leistungsvariabilität betroffen sein, insbesondere aufgrund von Kaltstarts. Ein Kaltstart tritt auf, wenn eine Funktion nach einer Phase der Inaktivität aufgerufen wird, was die Plattform dazu zwingt, eine neue Ausführungsumgebung zu initialisieren. Die Verzögerung kann je nach Folgendem variieren:
Dies kann latenzempfindliche Anwendungen beeinträchtigen. Häufige Ansätze zur Minderung umfassen:
Monitoring und Debugging
Das Monitoring serverloser Systeme ist aufgrund ihrer verteilten und kurzlebigen Natur komplexer als in traditionellen Architekturen. Herausforderungen umfassen:
Um dies anzugehen, benötigen Teams:
Ohne die richtige Werkzeuge wird es erheblich schwieriger, Leistungsprobleme oder Ausfälle zu identifizieren.
Begrenzte Kontrolle über die Umgebung
Serverless-Plattformen abstrahieren die Infrastruktur, was den Betriebsaufwand verringert, aber die Kontrolle einschränkt. Teams können in der Regel nicht:
Diese Einschränkungen können problematisch sein für:
Komplexe Zustandsverwaltung
Serverless-Funktionen sind von Natur aus zustandslos, was bedeutet, dass sie keine Daten zwischen den Ausführungen beibehalten. Um den Zustand zu verwalten, müssen Teams auf externe Dienste wie Folgendes zurückgreifen:
Während dies Skalierbarkeit ermöglicht, führt es auch zu:
Kostenunvorhersehbarkeit im großen Maßstab
Obwohl serverlos für variable Workloads kosteneffizient ist, können die Kosten im großen Maßstab unvorhersehbar werden. Dies geschieht typischerweise, wenn:
Da die Abrechnung an die Ausführung gebunden ist, können selbst kleine Ineffizienzen bei starker Nutzung zu erheblichen Kosten führen.
Ausführungszeitlimits
Serverless-Plattformen setzen maximale Ausführungszeitlimits für Funktionen (z.B. Minuten, abhängig vom Anbieter). Dies schafft Einschränkungen für:
Um dies zu umgehen, müssen Teams oft Systeme mit folgenden Mitteln neu gestalten:
Einhaltungs- und Sicherheitsbedenken
In regulierten Branchen (z.B. Gesundheitswesen, Fintech) führt serverlos zu zusätzlichen Herausforderungen bei der Compliance. Dazu gehören:
Organisationen müssen sicherstellen, dass:
Von Anbietern auferlegte Kontingente
Cloud-Anbieter setzen Limits (Kontingente) für die Nutzung von serverlosen Funktionen durch:
Diese Limits sind in der Regel für die meisten Anwendungen ausreichend, können jedoch zu einem Engpass werden, wenn:
Ohne Planung kann dies zu Drosselung und einer verschlechterten Leistung führen.
Analyse von Serverless vs. traditionellen Modellen
Ein Vergleich von serverlos mit traditionellen (selbstverwalteten) Infrastrukturen hebt grundlegende Unterschiede in der Art und Weise hervor, wie Systeme aufgebaut, skaliert und gewartet werden, und hilft, die Vorteile der serverlosen Architektur in realen Systemen besser zu verstehen. Die Wahl zwischen diesen Ansätzen hängt von der Art der Workloads, der Teamstruktur und langfristigen Kostenüberlegungen ab.
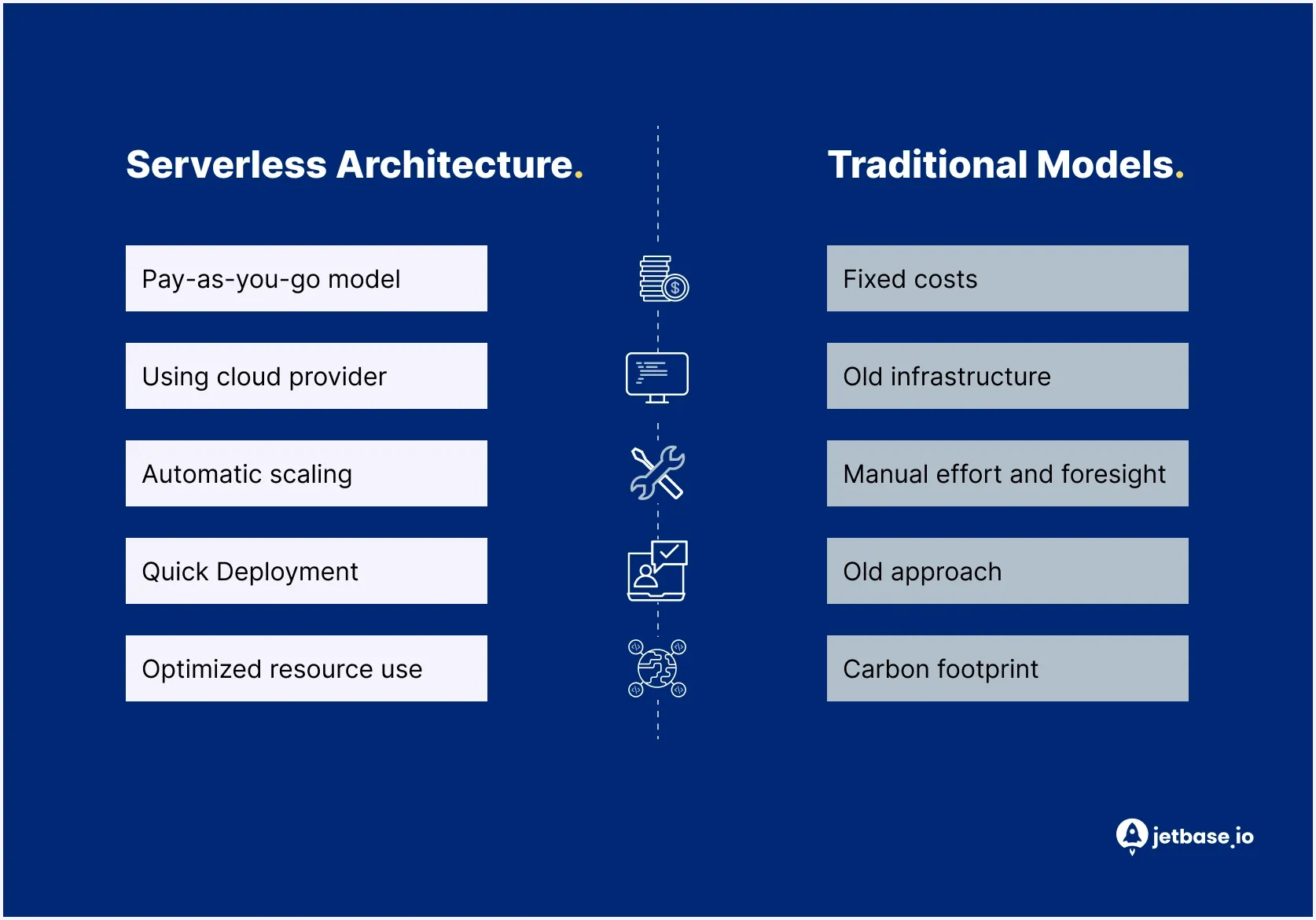
Preismodell
Traditionelle Infrastruktur basiert auf bereitgestellten Ressourcen, bei denen Unternehmen für zugewiesene Kapazitäten zahlen, unabhängig von der tatsächlichen Nutzung.
Dies macht die Kosten berechenbarer, führt aber oft zu ungenutzten Ressourcen.
Serverless folgt einem Pay-as-you-go-Modell, bei dem die Abrechnung auf der tatsächlichen Ausführungszeit und der Anzahl der Anfragen basiert.
In der Praxis:
Dieser Vergleich zeigt deutlich, wie die Vorteile von Serverless je nach Arbeitslastmustern variieren.
Betriebliche Aufwendungen und Wartung
In traditionellen Setups sind die Teams verantwortlich für die Verwaltung von:
Dies erfordert dedizierte DevOps-Bemühungen und kontinuierliche Wartung. Serverless verlagert diese Verantwortlichkeiten auf den Cloud-Anbieter, wodurch das Management der Infrastruktur entfällt und die Betriebskosten gesenkt werden.
Infolgedessen:
Skalierbarkeit und Leistung
Die Skalierung in traditionellen Infrastrukturen erfordert Planung und manuelle Konfiguration. Teams müssen Ressourcen im Voraus bereitstellen und die Kapazität basierend auf der erwarteten Last anpassen. Serverless skaliert automatisch basierend auf eingehenden Anfragen, wodurch Systeme Verkehrsspitzen ohne manuelles Eingreifen bewältigen können. Allerdings:
Innovation und Markteinführungszeit
Traditionelle Infrastruktur verlangsamt oft die Entwicklung aufgrund von Komplexität bei der Einrichtung, Konfiguration der Umgebung und Bereitstellungspipelines. Serverless verringert diese Barrieren, indem es die Abhängigkeiten von der Infrastruktur entfernt. In der Praxis:
Dies macht Serverless besonders effektiv für die Entwicklung von MVPs und schnelle Experimente.
Umweltauswirkungen
Traditionelle Infrastruktur führt oft zu Überprovisionierung, bei der ungenutzte Ressourcen weiterhin Energie verbrauchen. Serverless optimiert die Ressourcennutzung, indem es Code nur bei Bedarf ausführt, was den gesamten Energieverbrauch senken kann. Allerdings hängen die Umweltauswirkungen letztendlich von den Arbeitslastmustern und dem Systemdesign ab.
Wann man jede Methode wählen sollte
Wählen Sie serverless, wenn:
Wählen Sie traditionell (selbstverwaltete oder bereitgestellte Infrastruktur), wenn:
Letztendlich hängt die Bewertung der Vor- und Nachteile von serverless Architektur davon ab, Kosten, Skalierbarkeit und operativen Kontrolle auszubalancieren.
Serverless vs. Microservices: Eine Frage der Wahl?
Die Wahl zwischen serverless und Microservices wird oft missverstanden. Dies sind keine konkurrierenden Ansätze, sondern Konzepte, die auf unterschiedlichen Ebenen operieren. Das Verständnis der Vor- und Nachteile von serverless Architektur ist entscheidend, wenn es darum geht, diese Ansätze in realen Systemen zu kombinieren.
Microservices sind ein architektonisches Muster — eine Möglichkeit, eine Anwendung als Sammlung kleiner, unabhängiger Dienste zu strukturieren. Serverless hingegen ist ein Ausführungsmodell — eine Möglichkeit, diese Dienste zu betreiben und zu skalieren, ohne die Infrastruktur zu verwalten.
In der Praxis kann serverless verwendet werden, um Microservices zu implementieren. Jede Funktion kann einen kleinen, unabhängigen Dienst darstellen, der auf spezifische Ereignisse reagiert, was den Aufbau modularer und skalierbarer Systeme erleichtert. Microservices erfordern jedoch nicht serverless. Teams führen Microservices oft auf:
Wann man Serverless und Microservices kombinieren sollte
Das Kombinieren dieser Ansätze funktioniert gut, wenn:
In diesem Setup vereinfacht serverless die Bereitstellung und Skalierung, während Microservices eine klare Trennung von Belangen bieten.
Wann man Microservices ohne Serverless verwenden sollte
Das Ausführen von Microservices auf bereitgestellter Infrastruktur kann die bessere Wahl sein, wenn:
Wichtige Kompromisse zu berücksichtigen
Während die Kombination von serverless mit Microservices Flexibilität bietet, führt sie auch zu Komplexität.
Teams sollten Folgendes berücksichtigen:
Beispiele für serverlose Architektur
Serverlose Architektur wird häufig in verschiedenen Anwendungstypen eingesetzt, insbesondere dort, wo Arbeitslasten ereignisgesteuert, variabel oder eine schnelle Bereitstellung erfordern.
Im Folgenden sind gängige reale Anwendungsfälle aufgeführt, die die Vor- und Nachteile der serverlosen Architektur hervorheben und zeigen, wann sie am besten funktioniert und welche Kompromisse Teams berücksichtigen sollten.
| Anwendungsfall | Problem | Warum serverlos passt | Risiken und Einschränkungen |
|---|---|---|---|
| API-Backends | Der Aufbau skalierbarer APIs erfordert den Umgang mit unvorhersehbarem Verkehr, die Verwaltung der Infrastruktur und die Gewährleistung einer hohen Verfügbarkeit. | Serverlos ermöglicht es APIs, automatisch basierend auf eingehenden Anfragen zu skalieren, ohne die Infrastruktur im Voraus bereitzustellen. Das erleichtert den Umgang mit Verkehrsspitzen und reduziert den Betriebsaufwand. | |
| Webhooks und Ereignisverarbeitung | Systeme müssen oft in Echtzeit auf externe Ereignisse (z. B. Zahlungen, Benutzeraktionen, Integrationen von Drittanbietern) reagieren. | Serverlose Funktionen können sofort durch eingehende Ereignisse ausgelöst werden, was sie ideal für die Behandlung von Webhooks und ereignisgesteuerten Workflows macht. | |
| Geplante Aufgaben (Cron-Jobs) | Anwendungen benötigen oft wiederkehrende Hintergrundjobs wie Datenbereinigung, Berichtserstellung oder Systemabgleiche. | Serverlose Plattformen unterstützen geplante Trigger, die es Teams ermöglichen, Aufgaben auszuführen, ohne dedizierte Server warten zu müssen. | |
| Datenverarbeitungspipelines | Die Verarbeitung großer Datenmengen (z. B. Protokolle, Uploads, Analyseereignisse) erfordert skalierbare und effiziente Pipelines. | Serverlos ermöglicht die parallele Verarbeitung von Datenströmen und Ereignissen und erleichtert die dynamische Skalierung von Pipelines basierend auf der Last. | |
| Entwicklung von MVPs für Startups | Startups müssen schnell mit begrenzten Ressourcen starten, während sie eine Investition in die Infrastruktur im Voraus vermeiden. | Serverless ermöglicht es Teams, MVPs zu entwickeln und bereitzustellen, ohne Infrastruktur einzurichten, wodurch die Markteinführungszeit und die Anfangskosten sinken. |
Die Zukunft des Serverless Computing
Serverless Computing entwickelt sich von einem Nischenansatz zu einem Kernbestandteil moderner Cloud-Architekturen, was sowohl die Vorteile als auch die Nachteile der serverlosen Architektur widerspiegelt. Der Fokus verschiebt sich in Richtung besserer Leistung, mehr Kontrolle und Integration mit anderen Technologien.
| Trend | Was es in der Praxis bedeutet | Auswirkungen auf das Geschäft |
|---|---|---|
| Edge Computing | Funktionen werden näher bei den Endbenutzern an verteilten Standorten ausgeführt, wodurch die Distanz zwischen Benutzern und Verarbeitungslogik reduziert wird | Geringere Latenz, verbesserte Leistung für Echtzeitanwendungen, bessere Benutzererfahrung für globale Produkte |
| Serverless-Container | Containerisierte Anwendungen laufen in einem serverlosen Modell mit automatischer Skalierung und verwalteter Infrastruktur | Größere Kontrolle über Laufzeit und Abhängigkeiten, bessere Unterstützung komplexer Arbeitslasten, weniger Einschränkungen als bei Standardfunktionen |
| KI und Datenverarbeitung | Serverless wird für bedarfsorientierte Inferenz, ereignisgesteuerte Datenverarbeitung und automatisierte Pipelines verwendet | Kosteneffiziente KI-Ausführung, Fähigkeit zur dynamischen Skalierung der Datenverarbeitung, schnellere Entwicklung datengetriebener Funktionen |
| Hybride Architekturen | Serverless wird mit traditioneller Infrastruktur basierend auf den Arbeitslastanforderungen kombiniert | Bessere Kostenoptimierung, flexiblere Architekturgestaltung, Balance zwischen Skalierbarkeit und Kontrolle |
In der Praxis kombinieren die meisten modernen Systeme diese Ansätze, anstatt sich nur auf Serverless zu verlassen.
Diese Trends verdeutlichen weiter, wie sich die Vor- und Nachteile der serverlosen Architektur entwickeln, während sich die Technologie weiterentwickelt.
Sind Sie bereit, auf Serverless umzusteigen?
Die Übernahme der serverlosen Architektur ist nicht nur eine technische Entscheidung — sie erfordert die Bewertung von Arbeitslasten, Risiken und langfristiger Skalierbarkeit sowie das Verständnis der Vor- und Nachteile von Serverless. Bevor Teams zu Serverless wechseln, sollten sie bewerten, ob ihre Systeme und Ziele mit diesem Modell übereinstimmen.
Serverless Bereitschaftscheckliste
Serverless ist eine gute Wahl, wenn die meisten der folgenden Bedingungen zutreffen:
Wenn diese Bedingungen nicht erfüllt sind, kann serverless mehr Komplexität als Nutzen bringen.
Wesentliche Risiken, die zu beachten sind
Vor der Einführung sollten Teams sich der häufigsten Risiken bewusst sein:
Ein frühzeitiges Verständnis dieser Risiken hilft, kostspielige Neugestaltungen später zu vermeiden.
Schrittweise Migrationsstrategie
Ein erfolgreicher Übergang zu serverless sollte schrittweise und nicht sofort erfolgen.
Ein typischer Ansatz umfasst:
Dies reduziert das Risiko und ermöglicht es Teams, die Architektur schrittweise anzupassen.
Pilot-vor-alles-Ansatz
Anstatt eine vollständige Migration durchzuführen, sollten Teams mit einem Pilotprojekt beginnen.
Ein starker Pilot ist:
Ein erfolgreicher Pilot zeigt typischerweise:
Wann man Serverless vermeiden sollte
Serverless ist möglicherweise nicht die beste Wahl, wenn:
In diesen Fällen sind traditionelle oder hybride Architekturen oft geeigneter.
Letztendlich hängen die Vorteile von serverless davon ab, wie gut die Architektur mit Ihren spezifischen Produkt- und Arbeitslastanforderungen übereinstimmt.
Wenn Sie serverless in Betracht ziehen, kann JetBase Ihnen helfen, den richtigen Ansatz zu bewerten und einen reibungslosen Übergang zu planen.