Explorer les avantages et les inconvénients de l'architecture sans serveur révèle comment elle redéfinit la manière dont les entreprises déploient et gèrent des applications. Ce modèle de cloud computing supprime la nécessité de gérer des serveurs, permettant aux équipes de se concentrer sur la construction et la livraison des fonctionnalités des produits au lieu de gérer l'infrastructure.
Comprendre les avantages de l'architecture sans serveur et ses compromis est essentiel pour les équipes choisissant la bonne approche cloud.
Dans la pratique, l'architecture sans serveur est le plus souvent choisie dans des scénarios où la rapidité, la flexibilité et le contrôle des coûts sont critiques. Elle est couramment utilisée pour le développement de MVP, les systèmes basés sur des événements, et les applications avec un trafic imprévisible ou soudain. Dans ces cas, les équipes peuvent lancer plus rapidement, évoluer automatiquement et éviter les investissements initiaux dans l'infrastructure.
Cependant, le sans serveur n'est pas une solution universelle. Son efficacité dépend du type de charge de travail, de l'architecture système et de la stratégie de mise à l'échelle à long terme. Dans certains cas, cela peut introduire des limitations de performances, des coûts plus élevés à grande échelle ou un contrôle réduit sur l'environnement.
Cet article s'adresse aux CTO, fondateurs et équipes produit qui évaluent l'architecture sans serveur et qui ont besoin d'une compréhension claire et pratique de quand il est judicieux de l'utiliser.
Qu'est-ce que l'architecture sans serveur?
L'architecture sans serveur est un modèle de cloud computing où le fournisseur de cloud gère l'infrastructure sous-jacente, permettant aux équipes de développement de se concentrer entièrement sur la logique de l'application au lieu de la gestion des serveurs.
Malgré son nom, sans serveur ne signifie pas que les serveurs n'existent pas. Cela signifie que la fourniture, l'évolutivité et la maintenance de l'infrastructure sont gérées par des fournisseurs tels qu'AWS, Google Cloud ou Microsoft Azure. Les développeurs déploient du code sous forme de fonctions, qui ne sont exécutées que lorsque cela est nécessaire.
Ce modèle est souvent appelé Fonction en tant que Service (FaaS) et est couramment utilisé dans des applications modernes, natives du cloud, qui nécessitent flexibilité, évolutivité et cycles de livraison plus rapides.
Ces caractéristiques expliquent pourquoi le sans serveur est largement adopté dans le développement de produits modernes, en particulier pour les équipes qui privilégient la rapidité, l'évolutivité et la réduction des frais généraux opérationnels.
Comment fonctionne l'architecture sans serveur
Les applications sans serveur sont construites autour d'événements et d'exécutions de fonctions éphémères. Dans des projets concrets, les fonctions sans serveur sont généralement déclenchées par :
- des requêtes API (points de terminaison HTTP)
- des modifications de base de données (par exemple, nouvel enregistrement, mise à jour)
- des téléchargements de fichiers (par exemple, , images, documents)
- emplois planifiés (tâches cron)
- files d'attente de messages et systèmes de streaming
Une fois qu'un déclencheur se produit, le flux ressemble à ceci :
- L'événement est reçu par le fournisseur de cloud
- Une fonction est invoquée en réponse à cet événement
- La fonction s'exécute dans un environnement isolé
- Elle traite la demande et renvoie un résultat
- L'environnement d'exécution est terminé après achèvement
Ceci est connu comme un runtime éphémère — les fonctions ne s'exécutent pas en continu mais sont créées à la demande et détruites après exécution. D'un point de vue commercial, cela a un impact direct sur les coûts et l'évolutivité. Les équipes sont facturées uniquement pour le temps d'exécution réel, généralement mesuré en millisecondes. Cependant, la facturation peut devenir moins prévisible si :
- les fonctions sont déclenchées trop fréquemment
- le temps d'exécution n'est pas optimisé
- les processus d'arrière-plan sont mal conçus
Caractéristiques principales de l'architecture sans serveur
L'architecture sans serveur est définie par plusieurs principes fondamentaux qui façonnent la façon dont les systèmes sont conçus et opérés.
Architecture orientée événements
Les applications réagissent aux événements au lieu de fonctionner en continu. En pratique, cela signifie que les systèmes sont composés de petites fonctions indépendantes déclenchées par des actions utilisateur, des changements de système ou des intégrations externes.
Exécution sans état
Chaque exécution de fonction est indépendante et ne stocke pas de données entre les exécutions. Tout état requis doit être stocké de manière externe (par exemple, bases de données, services de stockage). Cela améliore l'évolutivité mais introduit une complexité supplémentaire dans la gestion des données et des flux de travail.
Infrastructure gérée
Le fournisseur de cloud s'occupe de :
- la provisionnement des serveurs
- l'évolutivité
- les patchs et la maintenance
- la haute disponibilité
Cependant, les équipes de développement sont toujours responsables de :
- la logique de l'application
- la conception de l'architecture
- les configurations de sécurité
- la surveillance et le contrôle des coûts
Évolutivité automatique
Les plateformes sans serveur mettent automatiquement à l'échelle les fonctions en fonction des demandes entrantes. Cela permet aux systèmes de gérer les pics de trafic sans intervention manuelle. En même temps, une mise à l'échelle incontrôlée peut entraîner :
- des coûts inattendus
- atteindre des limites de concurrence
- des goulets d'étranglement de performance dans les services en aval (par exemple, bases de données)
Les avantages de l'architecture sans serveur
Alors que nous explorons les avantages et les inconvénients de l'architecture sans serveur, il est important de comprendre que ses bénéfices dépendent fortement du type de charge de travail et de la conception du système.
Ces avantages sans serveur et bénéfices de l'informatique sans serveur deviennent clairs lorsqu'ils sont appliqués dans les bons scénarios.
Verrouillage des fournisseurs
Les solutions sans serveur sont étroitement liées aux écosystèmes des fournisseurs de cloud (par ex., AWS Lambda, Azure Functions, Google Cloud Functions). Cela crée une dépendance aux services, API et configurations spécifiques aux fournisseurs. En pratique, cela rend la migration entre fournisseurs complexe et coûteuse. Les stratégies d'atténuation courantes incluent :
- utiliser l'Infrastructure as Code (IaC) (par ex., Terraform) pour normaliser les déploiements
- abstraire la logique métier des services spécifiques aux fournisseurs
- concevoir des systèmes en gardant à l'esprit une portabilité partielle
Cependant, éviter complètement le verrouillage introduit souvent une complexité supplémentaire, en particulier dans les configurations multicloud, ce qui nécessite plus d'efforts d'ingénierie et de coordination.
Problèmes de performance
Les applications sans serveur peuvent rencontrer une variabilité de performance, en particulier en raison des démarrages à froid. Un démarrage à froid se produit lorsqu'une fonction est invoquée après une période d'inactivité, nécessitant que la plateforme initialise un nouvel environnement d'exécution. Le délai peut varier en fonction de :
- de l'environnement d'exécution (par ex., Node.js vs Java)
- de la taille de la fonction et de ses dépendances
- de la configuration du fournisseur de cloud
Cela peut impacter les applications sensibles à la latence. Les approches d'atténuation courantes incluent :
- la concurrence provisionnée (garder les fonctions chaudes)
- l'optimisation de la taille et des dépendances des fonctions
- l'utilisation de fonctions en périphérie lorsque cela est applicable
Surveillance et débogage
La surveillance des systèmes sans serveur est plus complexe que dans les architectures traditionnelles en raison de leur nature distribuée et éphémère. Les défis incluent :
- le manque d'environnements d'exécution persistants
- la difficulté à tracer les requêtes à travers plusieurs fonctions
- une visibilité limitée sur le comportement d'exécution
Pour y remédier, les équipes ont besoin de :
- d'outils de traçage distribué (par ex., AWS X-Ray, OpenTelemetry)
- systèmes de journalisation centralisés
- pratiques d'observabilité avancées
Sans les outils appropriés, identifier les problèmes de performance ou les pannes devient nettement plus difficile.
Contrôle limité sur l'environnement
Les plateformes sans serveur abstraient l'infrastructure, ce qui réduit l'effort opérationnel mais limite également le contrôle. Les équipes ne peuvent généralement pas :
- accéder au système d'exploitation sous-jacent
- personnaliser les environnements d'exécution au-delà des options prédéfinies
- contrôler les configurations de performance de bas niveau
Ces contraintes peuvent poser problème pour :
- les applications ayant des dépendances spécifiques au système
- les charges de travail critiques pour la performance
- les systèmes hérités nécessitant des environnements personnalisés
Gestion complexe de l'état
Les fonctions sans serveur sont sans état par design, ce qui signifie qu'elles ne conservent pas de données entre les exécutions. Pour gérer l'état, les équipes doivent s'appuyer sur des services externes tels que :
- des bases de données (SQL/NoSQL)
- des magasins en mémoire (par ex., Redis)
- le stockage d'objets (par ex., S3)
Bien que cela permet une évolutivité, cela :
- augmente la complexité architecturale
- introduit une latence supplémentaire
- nécessite une gestion attentive de la cohérence des données
Coût imprévisible à grande échelle
Bien que le serverless soit rentable pour des charges de travail variables, les coûts peuvent devenir imprévisibles à grande échelle. Cela se produit généralement lorsque :
- les fonctions sont déclenchées à haute fréquence
- le temps d'exécution n'est pas optimisé
- une architecture inefficace entraîne des invocations excessives
Comme la facturation est liée à l'exécution, même de petites inefficacités peuvent entraîner des coûts significatifs sous une forte utilisation.
Limites de temps d'exécution
Les plateformes serverless imposent des limites de temps d'exécution maximales pour les fonctions (par exemple, des minutes selon le fournisseur). Cela crée des contraintes pour :
- les processus de longue durée
- les tâches de traitement de données lourdes
- les flux de travail synchrones
Pour contourner cela, les équipes doivent souvent redessiner les systèmes en utilisant :
- des flux de travail asynchrones
- des files d'attente de tâches
- la chaîne de fonctions
Préoccupations en matière de conformité et de sécurité
Dans les secteurs réglementés (par exemple, la santé, la fintech), le serverless introduit des défis de conformité supplémentaires. Ceux-ci incluent :
- un contrôle limité sur l'emplacement et la configuration de l'infrastructure
- dépendance aux pratiques de sécurité du fournisseur
- la complexité à répondre aux exigences strictes de gouvernance des données
Les organisations doivent s'assurer que :
- le fournisseur cloud respecte les normes de conformité (par exemple, HIPAA, GDPR)
- des politiques d'accès et de traitement des données appropriées sont mises en œuvre
Quotas imposés par le fournisseur
Les fournisseurs cloud imposent des limites (quotas) à l'utilisation du serverless, y compris :
- la concurrence maximale
- les taux de demandes
- l'allocation de ressources par fonction
Ces limites sont généralement suffisantes pour la plupart des applications, mais peuvent devenir un goulot d'étranglement lorsque :
- les systèmes évoluent rapidement
- les pics de trafic dépassent les seuils attendus
- les quotas ne sont pas augmentés de manière proactive
Sans planification, cela peut entraîner une limitation et une dégradation des performances.
Analyse des modèles Serverless vs. Traditionnels
La comparaison du serverless à l'infrastructure traditionnelle (auto-gérée) met en évidence les différences fondamentales dans la manière dont les systèmes sont construits, évolués et maintenus, et permet de mieux comprendre les avantages de l'architecture serverless dans les systèmes réels. Le choix entre ces approches dépend du type de charge de travail, de la structure de l'équipe et des considérations de coûts à long terme.
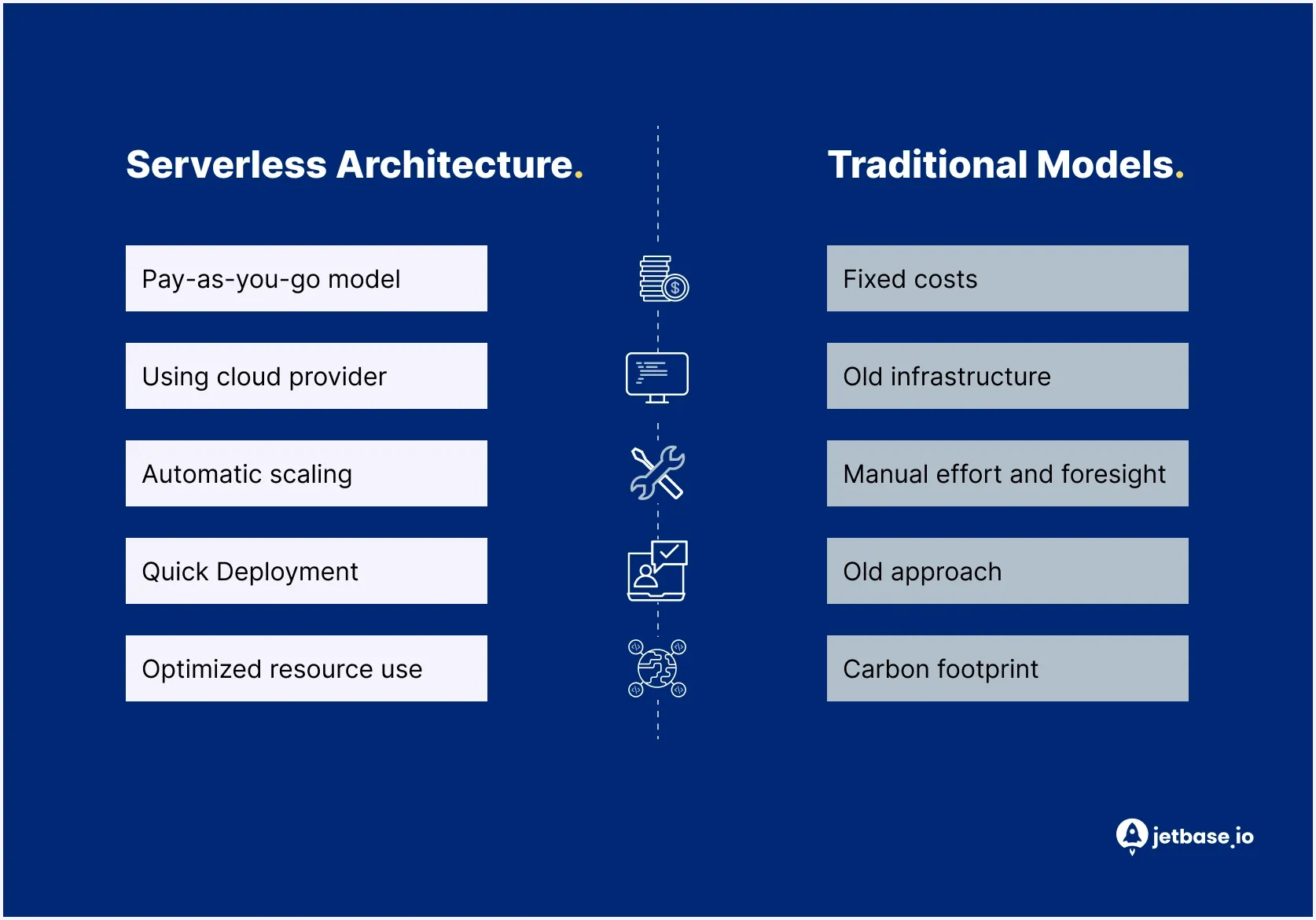
Modèle de tarification
L'infrastructure traditionnelle repose sur des ressources provisionnées, où les entreprises paient pour la capacité allouée, indépendamment de l'utilisation réelle.Cela rend les coûts plus prévisibles mais conduit souvent à des ressources sous-utilisées.
Serverless suit un modèle de paiement à l'usage, où la facturation est basée sur le temps d'exécution réel et le nombre de requêtes.
En pratique :
- serverless est plus rentable pour les charges de travail variables ou imprévisibles
- l'infrastructure traditionnelle est souvent plus rentable pour des charges de travail stables et constamment élevées
Cette comparaison montre clairement comment les avantages de serverless diffèrent selon les modèles de charge de travail.
Charges opérationnelles et maintenance
Dans les configurations traditionnelles, les équipes sont responsables de la gestion :
- des serveurs et des environnements
- des configurations de mise à l'échelle
- des correctifs et des mises à jour
Cela nécessite un effort DevOps dédié et une maintenance continue. Serverless transfère ces responsabilités au fournisseur de cloud, éliminant la gestion de l'infrastructure et réduisant les charges opérationnelles.
En conséquence :
- de plus petites équipes peuvent gérer des systèmes complexes
- l'effort d'ingénierie se concentre sur le développement de produits plutôt que sur la maintenance
Scalabilité et performance
La mise à l'échelle dans une infrastructure traditionnelle nécessite une planification et une configuration manuelle. Les équipes doivent provisionner des ressources à l'avance et ajuster la capacité en fonction de la charge attendue. Serverless se met à l'échelle automatiquement en fonction des requêtes entrantes, permettant aux systèmes de gérer des pics de trafic sans intervention manuelle. Cependant :
- la mise à l'échelle serverless est soumise à des limites de concurrence et de fournisseur
- les systèmes traditionnels offrent une performance plus prévisible sous une charge constante
Innovation et délai de mise sur le marché
L'infrastructure traditionnelle ralentit souvent le développement en raison de la complexité de la configuration, de la configuration de l'environnement et des pipelines de déploiement. Serverless supprime ces barrières en éliminant les dépendances infrastructurelles. En pratique :
- les équipes peuvent déployer plus rapidement et itérer plus fréquemment
- les startups et les petites équipes bénéficient le plus de la réduction du temps de configuration
Cela rend serverless particulièrement efficace pour le développement de MVP et l'expérimentation rapide.
Impact environnemental
L'infrastructure traditionnelle conduit souvent à une sur-provisionnement, où les ressources inutilisées consomment toujours de l'énergie. Serverless optimise l'utilisation des ressources en exécutant le code uniquement lorsque cela est nécessaire, ce qui peut réduire la consommation d'énergie globale. Cependant, l'impact environnemental dépend finalement des modèles de charge de travail et de la conception du système.
Quand choisir chaque approche
Choisissez sans serveur lorsque :
- vous construisez un MVP ou un produit en phase initiale
- les charges de travail sont basées sur des événements ou imprévisibles
- la vitesse de développement est une priorité
- vous souhaitez minimiser la charge DevOps
Choisissez l'infrastructure traditionnelle (auto-gérée ou provisionnée) lorsque :
- les charges de travail sont stables et constamment élevées
- la prévisibilité des coûts est cruciale
- vous avez besoin d'un contrôle total sur l'infrastructure et l'environnement d'exécution
- la cohérence des performances est une priorité
En fin de compte, l'évaluation des avantages et des inconvénients de l'architecture sans serveur dépend de l'équilibre entre les coûts, l'évolutivité et le contrôle opérationnel.
Sans serveur vs. Microservices : Question de choix ?
Le choix entre sans serveur et microservices est souvent mal compris. Ce ne sont pas des approches concurrentes mais des concepts qui opèrent à des niveaux différents. Comprendre les avantages et les inconvénients de l'architecture sans serveur est essentiel lors de la décision sur la manière de combiner ces approches dans des systèmes réels.
Les microservices sont un modèle architectural — une manière de structurer une application comme une collection de petits services indépendants. Sans serveur, en revanche, est un modèle d'exécution — une manière de faire fonctionner et d'évoluer ces services sans gérer l'infrastructure.
Dans la pratique, sans serveur peut être utilisé pour mettre en œuvre des microservices. Chaque fonction peut représenter un petit service indépendant qui répond à des événements spécifiques, facilitant ainsi la construction de systèmes modulaires et évolutifs. Cependant, les microservices ne nécessitent pas le sans serveur. Les équipes exécutent souvent des microservices sur :
- des conteneurs (par exemple, Kubernetes)
- des machines virtuelles
- une infrastructure auto-gérée ou provisionnée
Quand combiner sans serveur et microservices
Combiner ces approches fonctionne bien lorsque :
- les services sont basés sur des événements et faiblement couplés
- les charges de travail sont variables ou imprévisibles
- les équipes souhaitent réduire la gestion de l'infrastructure
Dans cette configuration, le sans serveur simplifie le déploiement et l'évolutivité, tandis que les microservices offrent une séparation claire des préoccupations.
Quand utiliser des microservices sans sans serveur
Exécuter des microservices sur une infrastructure provisionnée peut être un meilleur choix lorsque :
- les services sont de longue durée ou conservent l'état
- les charges de travail sont stables et constamment élevées
- les équipes nécessitent un contrôle granulaire sur l'environnement d'exécution et les performances
Principaux compromis à considérer
Bien que la combinaison de sans serveur avec des microservices offre de la flexibilité, elle introduit également de la complexité.
Les équipes devraient considérer :
- l'augmentation de la fragmentation du système (de nombreuses petites fonctions/services)
- une surveillance et un débogage plus complexes
- la dépendance aux services spécifiques au fournisseur
- une éventuelle augmentation des coûts avec des volumes de requêtes élevés
Exemples d'Architecture Serverless
L'architecture serverless est largement utilisée dans différents types d'applications, en particulier là où les charges de travail sont déclenchées par des événements, variables ou nécessitent un déploiement rapide.
Voici des cas d'utilisation réels courants qui mettent en évidence les avantages et les inconvénients de l'architecture serverless, montrant quand elle fonctionne le mieux et quels compromis les équipes devraient envisager.
| Cas d'utilisation | Problème | Pourquoi serverless convient | Risques & Limitations |
|---|---|---|---|
| Backends API | La construction d'API évolutives nécessite de gérer un trafic imprévisible, de gérer l'infrastructure et d'assurer une haute disponibilité. | Le serverless permet aux API de se mettre à l'échelle automatiquement en fonction des requêtes entrantes sans pré-provisionner l'infrastructure. Cela facilite la gestion des pics de trafic et réduit les frais de fonctionnement. |
|
| Webhooks et Traitement d'Événements | Les systèmes doivent souvent réagir à des événements externes (par exemple, paiements, actions des utilisateurs, intégrations tierces) en temps réel. | Les fonctions serverless peuvent être déclenchées instantanément par des événements entrants, les rendant idéales pour la gestion de webhooks et les flux de travail pilotés par des événements. |
|
| Tâches Planifiées (Jobs Cron) | Les applications nécessitent souvent des tâches d'arrière-plan récurrentes telles que le nettoyage des données, la génération de rapports ou la synchronisation des systèmes. | Les plateformes serverless supportent les déclencheurs programmés, permettant aux équipes d'exécuter des tâches sans maintenir des serveurs dédiés. |
|
| Pipelines de Transformation de Données | Le traitement de grands volumes de données (par exemple, journaux, uploads, événements d'analyse) nécessite des pipelines évolutifs et efficaces. | Le serverless permet le traitement parallèle des flux de données et des événements, facilitant l'évolutivité dynamique des pipelines en fonction de la charge. |
|
| Développement de MVP pour Startups | Les startups doivent se lancer rapidement avec des ressources limitées tout en évitant un investissement initial dans l'infrastructure. | Serverless permet aux équipes de créer et de déployer des MVP sans configurer d'infrastructure, réduisant ainsi le temps de mise sur le marché et les coûts initiaux. |
|
L'avenir de l'informatique sans serveur
L'informatique sans serveur évolue d'une approche de niche vers un composant central des architectures cloud modernes, reflétant à la fois les avantages et les inconvénients de l'architecture sans serveur. L'accent se déplace vers de meilleures performances, plus de contrôle et une intégration avec d'autres technologies.
| Tendance | Ce que cela signifie en pratique | Impact commercial |
|---|---|---|
| Informatique de périphérie | Les fonctions s'exécutent plus près des utilisateurs finaux dans des emplacements distribués, réduisant la distance entre les utilisateurs et la logique de traitement | Latence réduite, performances améliorées pour les applications en temps réel, meilleure expérience utilisateur pour les produits mondiaux |
| Conteneurs sans serveur | Les applications conteneurisées fonctionnent dans un modèle sans serveur avec mise à l'échelle automatique et infrastructure gérée | Meilleur contrôle sur l'exécution et les dépendances, meilleur support pour des charges de travail complexes, moins de limitations que les fonctions standard |
| IA et traitement des données | Le sans serveur est utilisé pour l'inférence à la demande, le traitement des données déclenché par des événements et les pipelines automatisés | Exécution d'IA rentable, capacité à mettre à l'échelle le traitement des données de manière dynamique, développement plus rapide de fonctionnalités basées sur les données |
| Architectures hybrides | Le sans serveur est combiné avec une infrastructure traditionnelle en fonction des exigences de charge de travail | Meilleure optimisation des coûts, conception d'architecture plus flexible, équilibre entre scalabilité et contrôle |
En pratique, la plupart des systèmes modernes combinent ces approches plutôt que de s'appuyer uniquement sur le sans serveur.
Ces tendances soulignent encore comment les avantages et les inconvénients de l'architecture sans serveur évoluent à mesure que la technologie mûrit.
Êtes-vous prêt à migrer vers le sans serveur ?
Adopter l'architecture sans serveur n'est pas seulement une décision technique : cela nécessite d'évaluer les charges de travail, les risques et la scalabilité à long terme, ainsi que de comprendre les avantages et les inconvénients du sans serveur. Avant de passer au sans serveur, les équipes doivent évaluer si leurs systèmes et objectifs s'alignent avec ce modèle.
Liste de Vérification de Préparation pour Serverless
Serverless est un bon choix si la plupart des conditions suivantes s'appliquent :
- les charges de travail sont déclenchées par des événements (API, webhooks, tâches en arrière-plan)
- le trafic est variable ou imprévisible
- le système ne repose pas sur des processus de longue durée
- un délai de mise sur le marché rapide est une priorité
- l'équipe souhaite réduire les frais généraux de DevOps
- l'architecture peut être conçue comme sans état
Si ces conditions ne sont pas remplies, le serverless pourrait introduire plus de complexité que de valeur.
Risques Clés à Considérer
Avant l'adoption, les équipes doivent être conscientes des risques les plus courants :
- croissance des coûts à l'échelle en raison d'exécutions fréquentes
- variabilité des performances (par exemple, démarrages à froid)
- verrouillage du fournisseur et dépendance vis-à-vis des services du fournisseur
- architecture système complexe (surtout avec de nombreuses fonctions)
- contrôle limité sur l'environnement d'exécution et l'infrastructure
Comprendre ces risques tôt aide à éviter des redesigns coûteux par la suite.
Stratégie de Migration Progressive
Une transition réussie vers le serverless devrait être progressive plutôt qu'immédiate.
Une approche typique comprend :
- identification des composants déclenchés par des événements à faible risque
- migration des charges de travail isolées (par exemple, tâches en arrière-plan, API)
- surveillance des performances, des coûts et de la fiabilité
- expansion de l'utilisation du serverless basée sur les résultats
Cela réduit le risque et permet aux équipes d'adapter l'architecture progressivement.
Approche Pilote d'Abord
Au lieu d'une migration complète, les équipes devraient commencer par un projet pilote.
Un bon pilote est :
- petit dans son étendue mais significatif
- facile à isoler des systèmes principaux
- mesurable en termes de performances et de coûts
Un pilote réussi démontre généralement :
- réduction des frais généraux d'infrastructure
- performances stables sous charge
- comportement des coûts prévisible
Quand Éviter Serverless
Serverless peut ne pas être le bon choix lorsque :
- les charges de travail sont de longue durée ou intensives en calcul
- le trafic est stable et constamment élevé
- un contrôle strict sur l'infrastructure est requis
- la latence doit être entièrement prévisible
Dans ces cas, les architectures traditionnelles ou hybrides sont souvent plus adaptées.
En fin de compte, les avantages du serverless dépendent de la manière dont l'architecture s'aligne avec les exigences spécifiques de votre produit et de vos charges de travail.
Si vous envisagez le serverless, JetBase peut vous aider à évaluer la bonne approche et à planifier une transition en douceur.